Bloomberg GPT、AlphaSense、Kensho 等美股 AI 金融工具深度解析:国内开发者如何正确使用美股行情数据 API
作者: TickDB Research · 发布: 2026/4/3 · 阅读: 269
标签: B 类, 美股, 金融 AI 工具
当华尔街的 AI 工具已经能自动读研报、查财报、生成交易信号,国内开发者如何借力?本文深度解析 Bloomberg GPT、AlphaSense、Kensho 等顶级工具的核心能力与技术护城河,并为你提供一套从个人开发者到量化团队都能用的美股数据接入方案。
引言:美股 AI 金融工具的“军备竞赛”
2026 年,美股市场的 AI 金融工具已经不再是“辅助功能”,而是投研流程的核心引擎。Bloomberg GPT 用 500 亿参数的大模型驱动彭博终端,AlphaSense 索引了超过 5 亿份金融文档,Kensho 让自然语言直接生成 SQL 查询。这些工具正在重新定义“什么是高效的投研”。
对于国内开发者而言,理解这些工具的技术逻辑,不是为了“羡慕”,而是为了借鉴其设计思想,构建属于自己的美股分析系统。本文分为三部分:
- 第一部分:深度拆解 Bloomberg GPT、AlphaSense、Kensho、Hebbia 的核心能力与技术护城河
- 第二部分:针对不同需求的国内开发者,提供分层的美股数据接入方案(个人学习、量化团队、多资产策略)
- 第三部分:以 TickDB 为例,介绍如何通过统一行情 API 高效接入美股实时数据(覆盖 12,408 只美股),并展示 ClawHub 生态与实战效果
第一章:四大美股 AI 金融工具深度拆解
1.1 Bloomberg GPT:金融大模型的“天花板”
一句话亮点:把彭博终端 40 年的数据,装进了一个能对话的 AI。
#### 核心能力
Bloomberg GPT 是一款拥有 500 亿参数 的金融领域大语言模型,由彭博基于其 40 年积累的专有数据训练而成。它被集成到彭博终端的 ASKB 系统 中,用户可以通过自然语言直接查询终端内的所有数据。
你能用它做什么?
- 问:“最近一个月苹果公司的卖方评级变化趋势?” → AI 自动检索研报,生成趋势图。
- 问:“特斯拉和福特在 2024 年的自由现金流对比?” → AI 提取财报数据,生成对比表格。
- 问:“美联储最近三次议息会议对科技股的 sentiment 变化?” → AI 分析新闻和研报,输出情感曲线。
#### 技术护城河
| 护城河 | 具体说明 |
|---|---|
| 专有数据壁垒 | 40 年的交易数据、公司财务、宏观经济指标、新闻稿、研报,总量达 PB 级,外部无法复制 |
| 多智能体架构 | ASKB 系统通过主代理调度多个专家代理(财报、新闻、宏观),实现复杂任务分解 |
| 金融领域微调 | 在金融 NER、情感分析、术语理解上,显著优于通用大模型(如 GPT-4) |
#### 为什么值得尝试?
如果你有机会使用彭博终端,Bloomberg GPT 会让你体验到“对话式投研”的魔力。即使没有,它的设计思路也值得借鉴:专有数据 + 多 Agent 协作 = 不可替代的竞争力。
1.2 AlphaSense:定性研究的“搜索引擎”
一句话亮点:5 亿份文档的智能索引,让你搜到别人搜不到的信息。
#### 核心能力
AlphaSense 索引了 超过 5 亿份 金融文档,包括上市公司财报、电话会议记录、监管文件、卖方研报、新闻等。通过收购 Tegus,其专家访谈记录库已达 24 万份。核心功能有两个:
- Smart Synonyms(智能同义词):输入“供应链问题”,它能自动匹配到“物流中断”“产能不足”“交付延迟”等语义相近的段落。
- Generative Grid:跨数千份文档自动提取关键 KPI,生成对比表格。例如:“提取过去五年可口可乐和百事可乐在亚太地区的季度营收。”
#### 技术护城河
| 护城河 | 具体说明 |
|---|---|
| 文档规模 | 5 亿+ 份文档,覆盖绝大多数公开及半公开金融文本 |
| 语义检索 | 基于深度学习的句子嵌入模型,检索精度远超关键词匹配 |
| 独家数据 | 24 万份专家访谈记录,竞争对手无法短期内复制 |
#### 为什么值得尝试?
AlphaSense 目前有免费试用版,你可以上传自己的文档(如内部研报、会议记录),体验其跨文档检索能力。对于做行业研究或竞争分析的开发者,这款工具能节省 80% 的阅读时间。
1.3 Kensho(S&P Global):结构化数据的“AI 接口”
一句话亮点:用自然语言问 S&P 的数据库,它帮你写 SQL、画图表。
#### 核心能力
Kensho 专注于将 S&P Global 庞大的结构化金融数据(指数成分、公司财务、行业分类)转化为 AI 可调用的服务。其最新进展是推出了支持 模型上下文协议(MCP) 的 LLM 就绪 API。
你能用它做什么?
- 问:“找出过去五年毛利率连续增长的标普 500 成分股。” → Kensho 自动生成 SQL,返回股票列表。
- 问:“对比苹果、微软、谷歌的研发支出占营收比例。” → Kensho 提取数据,生成折线图。
#### 技术护城河
| 护城河 | 具体说明 |
|---|---|
| 数据权威性 | S&P Global 的指数、评级、基本面数据是金融行业的参考标准 |
| MCP 协议领先 | 率先支持 MCP,AI Agent 可以像调用本地函数一样调用 Kensho API |
| NL-to-SQL | 自然语言直接生成复杂 SQL,降低数据查询门槛 |
#### 为什么值得尝试?
Kensho 的 MCP API 目前有开发者试用计划。如果你正在构建 AI Agent,可以尝试将 Kensho 集成到你的工具链中,让 AI 自动查询结构化金融数据。
1.4 Hebbia:私有文档的“AI 原生”分析平台
一句话亮点:上传 1000 份 PDF,问它“哪几份的赔偿条款对我最不利”。
#### 核心能力
Hebbia 是一个 AI 原生平台,允许分析师一次性上传数千份私有文档(如并购协议、法律合同、内部备忘录),并进行复杂的推理查询。它的杀手锏是 句子级的精确引用追踪——AI 生成的每一个结论,都能追溯到源文档中的具体句子。
#### 技术护城河
| 护城河 | 具体说明 |
|---|---|
| 长上下文推理 | 支持一次性处理数十万 token 的文档集,进行跨文档关联分析 |
| 引用可解释性 | 每个答案都附带源文档中的具体句子,满足审计要求 |
| 私有部署 | 面向金融机构提供私有化部署,数据不出客户环境 |
#### 为什么值得尝试?
Hebbia 目前面向企业提供试用。如果你是做尽职调查、法律文档审查或内部知识库管理,这款工具会让你惊叹“原来 AI 可以这么用”。
第二章:国内开发者如何正确接入美股数据?——分层方案与避坑指南
不同需求的用户,对美股数据的需求完全不同。本章将针对 个人开发者/爱好者、量化策略团队、多资产策略开发者 三类人群,分别给出最优方案、常见缺陷及解决方案。
2.1 三类用户的核心需求
| 用户类型 | 核心需求 | 数据量级 | 延迟要求 | 预算 |
|---|---|---|---|---|
| 个人开发者/爱好者 | 学习量化、验证策略想法 | 少量股票,日线为主 | 分钟级可接受 | 免费或极低 |
| 量化策略团队 | 实盘交易、策略回测 | 全市场扫描,tick 级 | 实时(<100ms) | 中等(年费 $1k-$10k) |
| 多资产策略开发者 | 同时覆盖美股、A股、港股、加密货币 | 跨市场,多品种 | 实时 | 中等至高 |
2.2 方案一:个人开发者/爱好者——免费开源库 + 缓存优化
推荐方案:yfinance + pandas + 本地缓存
优点:零成本,代码简单,社区教程多。
不足:数据延迟高(分钟至小时级),盘中可能断流,美股盘前盘后数据不完整。
如何解决不足?
# 示例:带本地缓存的 yfinance 调用
import yfinance as yf
import pickle
from datetime import datetime
def get_stock_with_cache(symbol, cache_minutes=5):
cache_file = f"{symbol}.pkl"
if os.path.exists(cache_file):
mtime = datetime.fromtimestamp(os.path.getmtime(cache_file))
if (datetime.now() - mtime).seconds < cache_minutes * 60:
with open(cache_file, 'rb') as f:
return pickle.load(f)
data = yf.Ticker(symbol).history(period="1d")
with open(cache_file, 'wb') as f:
pickle.dump(data, f)
return data
优化技巧:
- 本地缓存:避免频繁请求,5 分钟内重复读取缓存。
- 多线程:同时获取多只股票,减少等待时间。
- 盘后数据:使用
yf.download(..., prepost=True)获取盘前盘后价格。
适合场景:学习量化、日线级别策略回测、非交易时段的离线分析。
2.3 方案二:量化策略团队——专业数据 API + 香港中继架构
推荐方案:境外专业 API(如 Polygon.io、Alpha Vantage)+ 香港代理节点
优点:低延迟(Polygon 中位延迟 <20ms),数据质量高,支持 WebSocket 实时推送。
不足:需要美元支付,国内直连延迟较高(180-220ms),连接稳定性受国际网络影响。
如何解决不足?——香港中继架构
内地服务器 ←→ 香港代理节点 ←→ Polygon WebSocket
- 原理:在香港部署一台轻量云服务器(如 AWS Hong Kong),保持与 Polygon 的持久 WebSocket 连接。内地服务器只与香港节点通信,利用香港到美西的低延迟(约 130-150ms)和内地到香港的低延迟(约 20-30ms),整体延迟可控在 160-180ms。
- 成本:香港轻量云服务器约 $10-20/月。
- 代码示例(香港节点转发):
# 香港节点:接收 Polygon 数据并缓存到 Redis
import asyncio
import websockets
import redis
r = redis.Redis(host='localhost', port=6379)
async def polygon_handler():
uri = "wss://socket.polygon.io/stocks"
async with websockets.connect(uri) as ws:
await ws.send('{"action":"auth","params":"YOUR_API_KEY"}')
await ws.send('{"action":"subscribe","params":"T.AAPL"}')
async for message in ws:
r.lpush("polygon:ticks", message)
# 内地服务器:从香港 Redis 拉取数据
import redis
r = redis.Redis(host='hongkong-node-ip', port=6379)
tick = r.rpop("polygon:ticks")
优化技巧:
- 使用 Redis 做消息队列:香港节点推送数据到 Redis,内地服务器批量拉取,减少 HTTP 请求。
- 边缘推理:将模型部署在美西云服务器(如 AWS us-west-1),只将交易信号传回内地。
- 降级方案:当 WebSocket 断开时,自动降级到 REST API 轮询。
适合场景:实盘交易、高频策略、需要低延迟的全市场扫描。
2.4 方案三:多资产策略开发者——统一行情 API(以 TickDB 为例)
推荐方案:TickDB 统一行情 API
定位:TickDB 可视为 “亚洲版 Polygon”,专为国内开发者优化网络链路,一套接口覆盖美股、A股、港股、加密货币、黄金/外汇。
核心能力:
- 美股覆盖:12,408 只,含纽交所、纳斯达克全部上市股票(代码格式如
AAPL.US) - 数据类型:实时行情快照、历史 K 线(1m~1M 周期)、订单簿深度、最近成交
- 接入方式:REST API + WebSocket 实时推送
- AI 友好:提供标准化 SKILL 文件,AI 助手可直接理解并调用
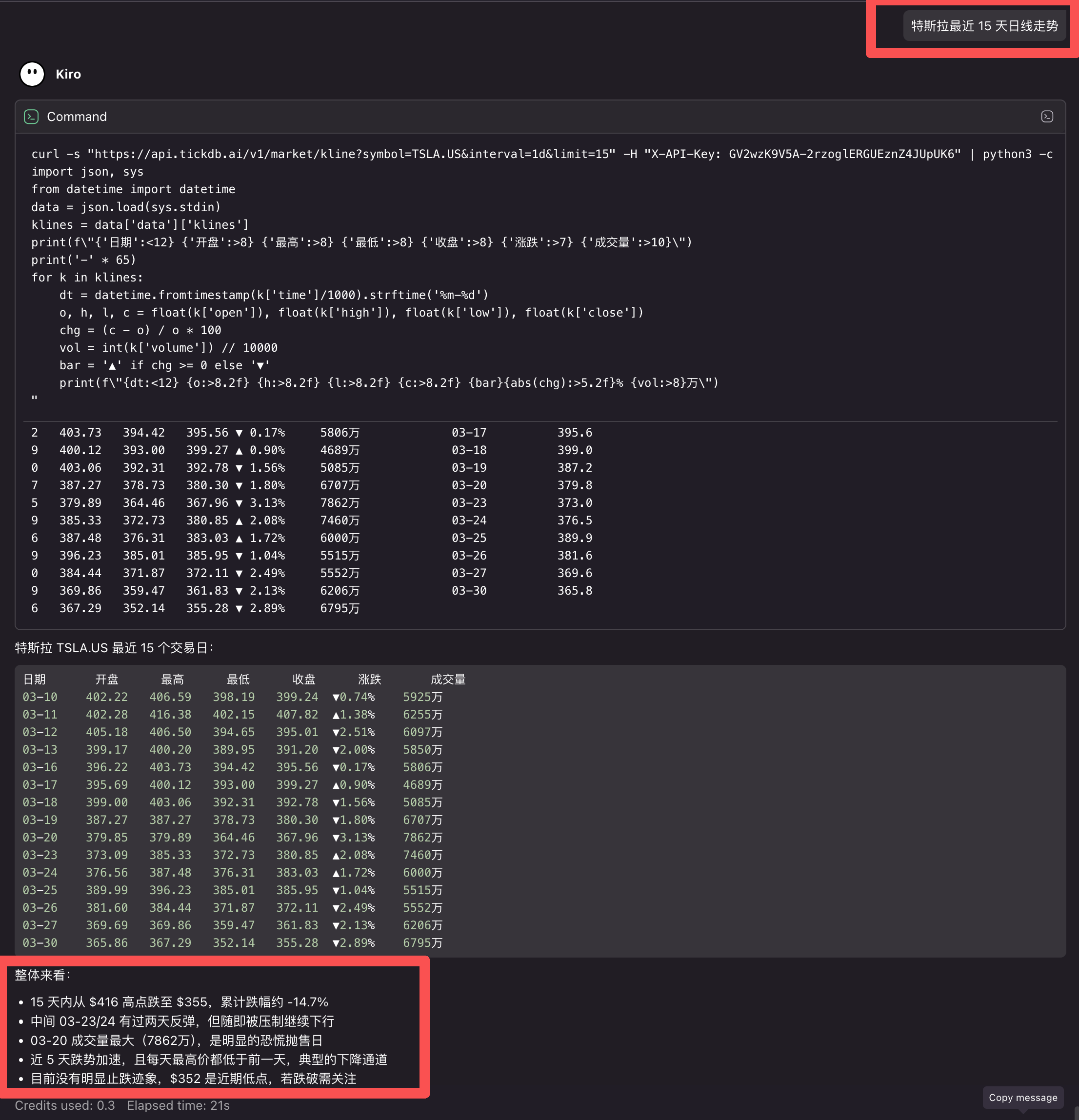
举例:Kiro 调用 TickDB 获取特斯拉日线数据
!微信图片_2026-03-31_094616_214.png
{kind=link}
代码示例:
import requests
API_KEY = "your_api_key"
url = "https://api.tickdb.ai/v1/market/kline"
params = {"symbol": "TSLA.US", "interval": "1d", "limit": 15}
response = requests.get(url, headers={"X-API-Key": API_KEY}, params=params)
klines = response.json()["data"]["klines"]
AI Skill 集成:TickDB 提供了标准的 SKILL 文件。将 SKILL 文件内容喂给 AI 助手后,你可以直接说“帮我获取苹果公司最近 30 天的日 K 线”,AI 会自动生成正确的调用代码。
ClawHub 生态:在 ClawHub 中搜索 “real-time market data”。
!ScreenShot_2026-04-03_152345_058.png
{kind=link}
2.5 三种方案对比总结
| 方案 | 适用人群 | 年成本 | 延迟 | 数据覆盖 | 技术门槛 |
|---|---|---|---|---|---|
| 免费库 + 缓存 | 个人学习 | $0 | 分钟~小时 | 有限 | 低 |
| 专业 API + 香港中继 | 量化团队 | $1k-$10k | <200ms(跨境) | 全市场 | 中高 |
| 统一 API(TickDB) | 多资产开发者 | 免费+付费 | 国内直连低延迟 | 12,408 只美股 + 多市场 | 低 |
结语:选对工具,让美股数据为你所用
Bloomberg GPT、AlphaSense、Kensho 等工具的强大,本质是“专有数据 + 先进架构”的胜利。对于国内开发者,我们无法复制彭博的 40 年数据积累,但可以通过选择合适的行情 API,构建属于自己的美股分析系统。
无论你是个人开发者、量化团队还是多资产策略构建者,都有一条适合你的路径:
- 入门:yfinance + 本地缓存,零成本验证想法。
- 专业:Polygon + 香港中继,追求低延迟与数据质量。
- 多资产:TickDB 统一接口,一套代码覆盖全球市场,12,408 只美股 + AI Skill 加持 + ClawHub 生态。
希望本文能帮你迈出第一步。如果你正在尝试接入美股数据,欢迎在评论区分享你的方案。
风险提示:本文内容仅为技术分析与行业观察,不构成任何投资建议。金融市场存在风险,决策需谨慎。
参考文献
[1] Bloomberg. "BloombergGPT: A Large Language Model for Finance." 2023.
[2] AlphaSense. "Product Overview 2026."
[3] S&P Global. "Kensho MCP API Documentation." 2026.
[4] Hebbia. "AI Platform for Private Documents." 2026.
[5] Polygon.io. "Market Data API Specifications." 2026.
[6] TickDB. "Unified Real-Time Market Data API Documentation v1.0.1." 2026.
[7] TickDB. "SKILL 文件 - AI 助手集成指南." 2026.
[8] ClawHub. "Skill Marketplace - real-time market data search results." 2026.
通过 TickDB API 获取实时行情数据
一个 API 接入外汇、加密货币、美股、港股、A股、贵金属和全球指数的实时行情。支持 WebSocket 低延迟推送,免费开始使用。
免费领取 API Key查看 API 文档