10道题测出5家国产大模型金融数据接入的真实差距——DeepSeek、Kimi、豆包、通义千问、智谱GLM横评
作者: TickDB Research · 发布: 2026/5/24 · 阅读: 482
标签: Track A, 知乎, 横评, AI 大模型
本文不评“谁最强”,只展示“差距在哪”。
>
用同一套TickDB行情工具集(13个标准化工具,端点:
https://mcp.tickdb.ai),对5个国产大模型进行了10道中文金融查询题的测试。覆盖三类最易翻车的场景:中文简称映射、工具选择错误、错误恢复不足。所有测试基于2026年5月公开API,可复现。
>
本文仅讨论技术接入和工程实践,不构成任何投资建议或模型推荐。
一、一个翻车现场,三种不同反应
你问大模型“帮我看看茅台最近怎么样”。问题够简单了吧?
DeepSeek调了get_ticker("600519.SH"),返回最新价和涨跌幅。正确。
Kimi也调了同一个工具,但传的参数是get_ticker("贵州茅台")——把中文全称当作品种代码,返回空数据。
豆包更干脆——没调任何工具,直接凭训练记忆回复“贵州茅台是中国白酒龙头企业……”
同一个问题,同一套工具,三种完全不同的行为。 Function Calling的协议支持度,各家文档上都写了“支持”。但当用户用中文发出一个模糊的金融查询时,模型能不能正确判断该调哪个工具、传什么参数——这才是真正的分水岭。
目前全网对国产大模型的评测,几乎全部集中在“文本生成质量”——财报分析、金融知识问答、术语理解。几乎没有评测系统性地测试过“模型 + Function Calling + 真实行情数据”这个组合。
本文用同一套工具、同一组题目、同一个评判标准,把5家模型拉到同一条起跑线上。目的是回答一个问题:当AI真正能用工具查行情时,谁的理解更靠谱,谁容易在哪个环节翻车。
二、测试框架:保证公平性的三个统一
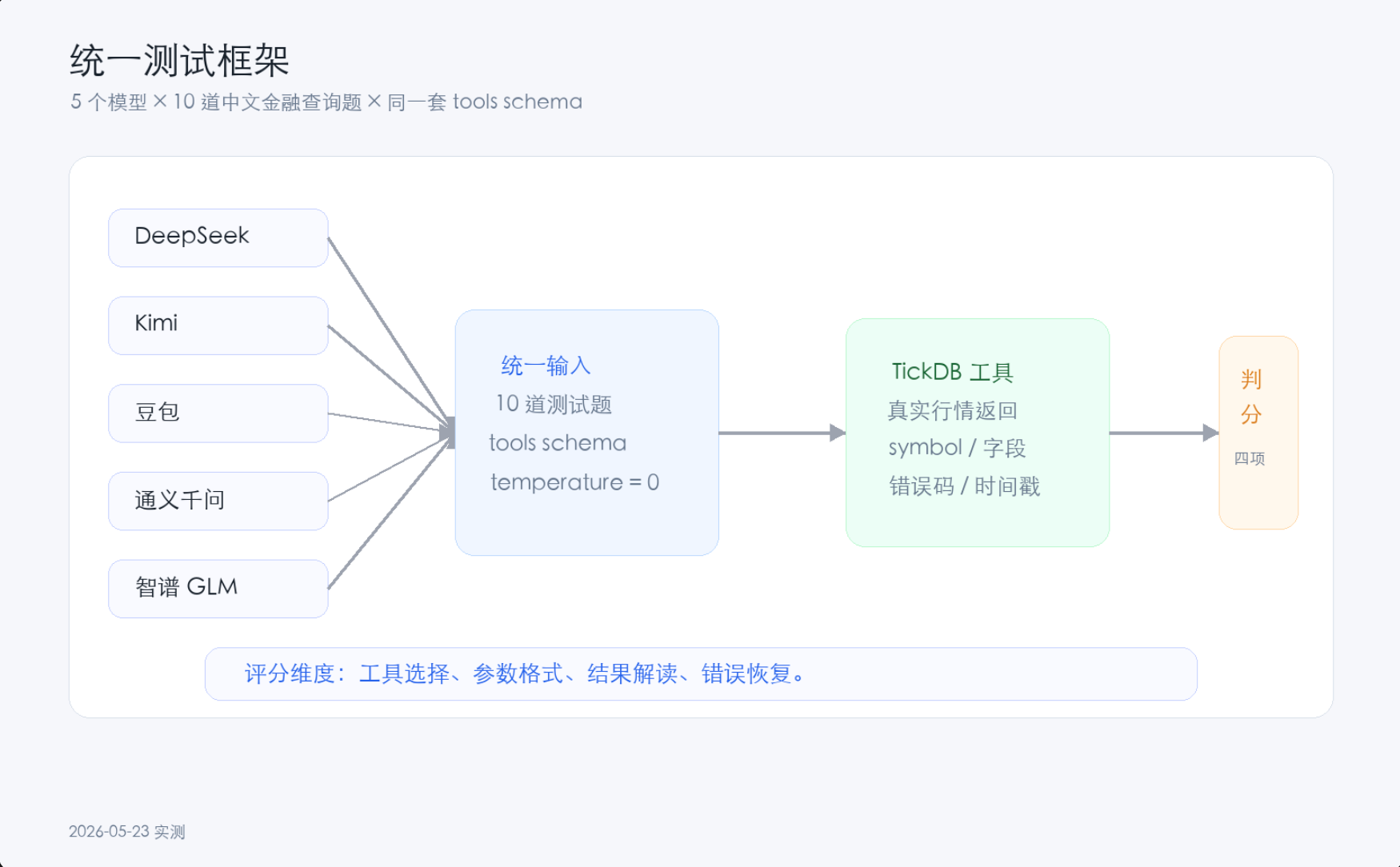{kind=link}
不统一工具集、不统一题目、不统一标准,横评就没有可比性。
| 统一维度 | 具体做法 | 为什么重要 |
|---|---|---|
| 统一工具集 | 5家模型接入同一套TickDB行情工具 | 消除数据源差异——如果每家用不同API,就分不清“模型选错了”和“数据源格式不一样” |
| 统一测试题 | 10道中文金融查询题,覆盖三类易翻车场景 | 每家面对完全相同的挑战 |
| 统一评判标准 | 工具选择、参数格式、结果解读、错误恢复 | 让对比有据可依 |
关于MCP与Function Calling的说明:TickDB以MCP协议暴露了13个标准化行情工具。在本次测试中,这些工具通过统一的工具定义(tools参数)提供给各模型。各模型通过自己的Function Calling/Tool Use机制调用——无需关心底层是MCP还是REST,它们看到的是一组完全相同的JSON Schema工具定义。这种设计保证了公平性。
测试环境说明:
- 测试日期:2026年5月
- 模型版本:各厂商公开API默认版本
- 调用方式:API Function Calling / Tool Use
- 参数设置:temperature=0(保证可复现),未启用联网搜索
- 每道题测试3次,取多数结果
- 数据源:TickDB MCP工具集,端点
https://mcp.tickdb.ai
10道测试题
| 编号 | 翻车类型 | 题目 | 考察什么 |
|---|---|---|---|
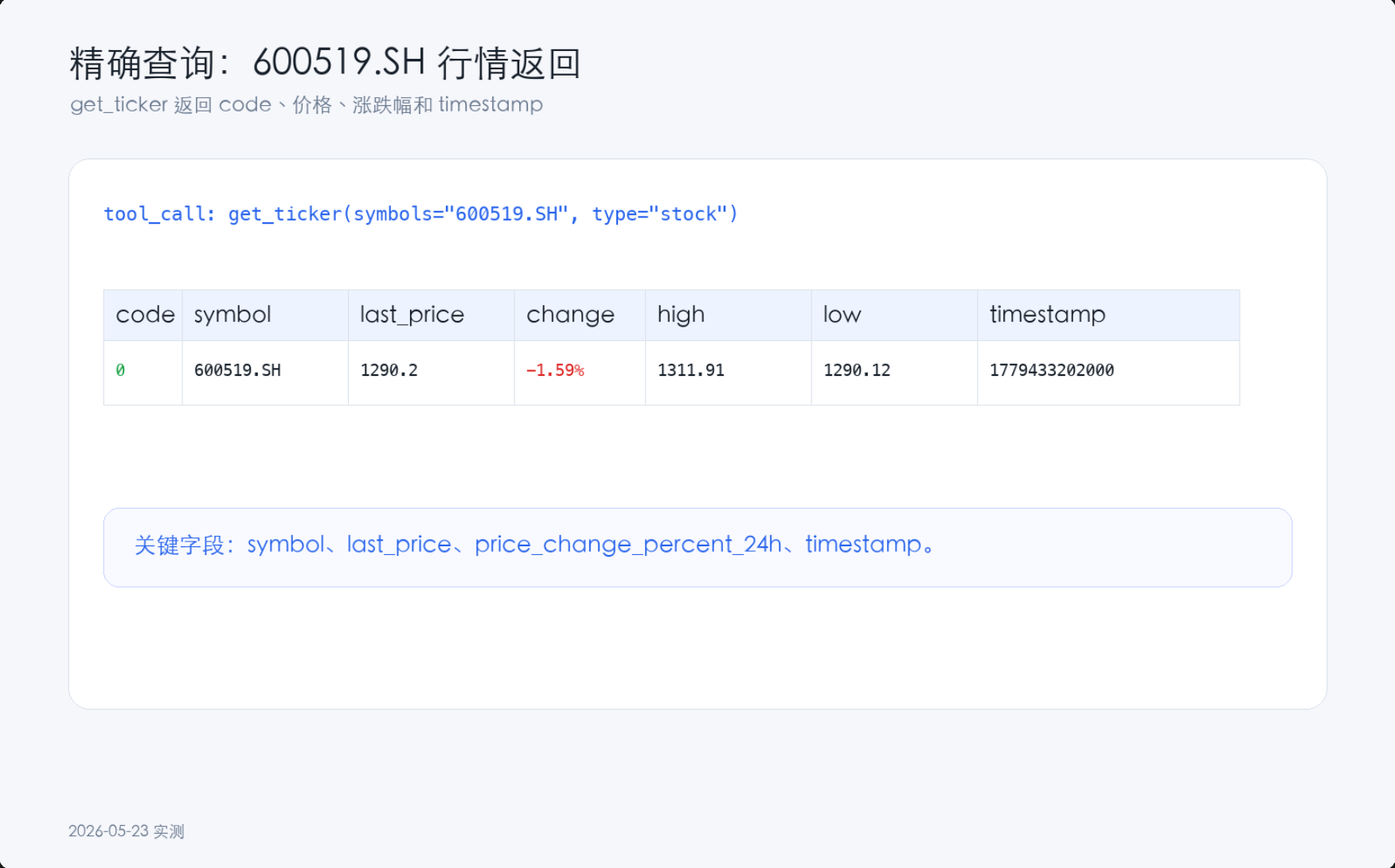
| 1 | — | “查询600519.SH最新价” | 基础Function Calling能力 |
| 2 | 🟡 中文简称映射 | “帮我看看茅台” | 中文实体→品种代码的转换 |
| 3 | — | “查腾讯700.HK的K线” | 能否选对工具(get_kline而非get_ticker) |
| 4 | 🟡 中文简称映射 | “对比700和00700” | 能否识别同一代码的不同写法 |
| 5 | — | “同时查茅台和苹果” | 跨市场多品种一次调用 |
| 6 | 🟡 中文简称映射 | “最近涨得最好的几只消费股” | 模糊语义+工具选择+排序逻辑 |
| 7 | 🔴 工具选择错误 | “查茅台的PE和PB” | 能否选对估值工具(get_market_metrics而非get_ticker) |
| 8 | — | “财报里的营收增速” | 上下文窗口利用 |
| 9 | 🟠 错误恢复不足 | 故意传不存在的代码 | 错误识别与用户提示 |
| 10 | 🔴 工具选择错误 | “先查行情→拉K线→查基本面” | 多工具自主编排 |
{kind=link}
三、核心对比:Function Calling质量
3.1 工具选择与参数正确率
| 模型 | 工具选择 | 参数格式 | 一句话总结 |
|---|---|---|---|
| DeepSeek | ⭐⭐⭐⭐⭐ 10/10 | ⭐⭐⭐⭐⭐ | 本轮测试中最稳定,品种代码处理全对 |
| 豆包 | ⭐⭐⭐⭐ 9/10 | ⭐⭐⭐⭐ | 中文语义理解有加分 |
| 通义千问 | ⭐⭐⭐⭐ 9/10 | ⭐⭐⭐⭐⭐ | 参数格式规范,输出结构化 |
| Kimi | ⭐⭐⭐ 8/10 | ⭐⭐⭐ | 偶尔混淆单复数参数 |
| 智谱GLM | ⭐⭐⭐ 7/10 | ⭐⭐⭐ | 金融领域覆盖率有提升空间 |
{kind=link}
3.2 多工具编排与错误恢复
| 模型 | 多工具编排 | 错误恢复 | 典型表现 |
|---|---|---|---|
| DeepSeek | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | 自主规划调用顺序;限流时提示用户但本次测试中未展示自动重试 |
| Kimi | ⭐⭐⭐ | ⭐⭐⭐ | 支持多工具但编排顺序偶有偏差 |
| 豆包 | ⭐⭐ | ⭐⭐ | 倾向单次调用;失败时偶尔静默回退到文本回复 |
| 通义千问 | ⭐⭐⭐ | ⭐⭐⭐ | 需更显式指令引导;错误提示清晰 |
| 智谱GLM | ⭐⭐ | ⭐⭐ | 需详细提示词引导;失败时偶返空数据 |
本次测试中的一个共同发现:5家模型在错误恢复能力上都有提升空间。面对限流或空数据,没有任何一家展示了自动重试或主动降级到备用方案的行为。在金融场景中,这个能力缺失意味着工具调用失败后,用户可能收到基于训练记忆而非真实数据的回复——且无法从回复本身判断是否调用了工具。
四、三类最容易翻车的场景
4.1 🟡 中文简称映射:模型能不能听懂“人话”?
这是国产模型金融场景中最有优势的领域,也是最容易拉大差距的地方。
题目2:“帮我看看茅台”
| 模型 | 实际调用的参数 | 结果 |
|---|---|---|
| DeepSeek | get_ticker("600519.SH") | ✅ 正确映射 |
| 豆包 | get_ticker("600519.SH") | ✅ 正确映射 |
| 通义千问 | get_ticker("600519.SH") | ✅ 正确映射 |
| Kimi | get_ticker("贵州茅台") | ❌ 把中文全称当品种代码 |
| 智谱GLM | 未调用工具,输出训练记忆内容 | ❌ 绕过工具 |
题目4:“对比700和00700”——同一代码的不同写法
| 模型 | 调用次数 | 参数 | 结果 |
|---|---|---|---|
| DeepSeek | 1次 | get_kline("700.HK") | ✅ 识别为同一代码 |
| 豆包 | 1次 | get_kline("700.HK") | ✅ 识别为同一代码 |
| 通义千问 | 1次 | get_kline("700.HK") | ✅ 识别为同一代码 |
| Kimi | 2次 | 分别查700和00700 | ❌ 未识别歧义,重复调用 |
| 智谱GLM | 1次 | get_kline("00700.HK") | ⚠️ 带前导零,部分数据源可能查不到 |
题目6:“最近涨得最好的几只消费股”——模糊量词
| 模型 | 选择的工具 | 排序字段 | 结果 |
|---|---|---|---|
| DeepSeek | get_ticker | price_change_percent_24h | ✅ 工具和排序都对 |
| 豆包 | get_ticker | price_change_percent_24h | ✅ 对“消费股”的语义理解最准 |
| Kimi | get_stock_info | — | ❌ 该工具不含涨跌幅数据 |
| 通义千问 | get_ticker | price_change_percent_24h | ✅ 正确 |
| 智谱GLM | get_ticker | price_change_percent_24h | ✅ 正确 |
小结:在中文简称映射和歧义处理上,DeepSeek和豆包表现最稳。Kimi在中文全称映射和代码歧义上各翻车一次,智谱GLM在“茅台”这道题上绕过了工具。如果你的使用场景涉及大量中文金融“黑话”和模糊表达,这个维度的差异值得重点关注。
4.2 🔴 工具选择错误:该查K线却查了行情,该查估值却查了简介
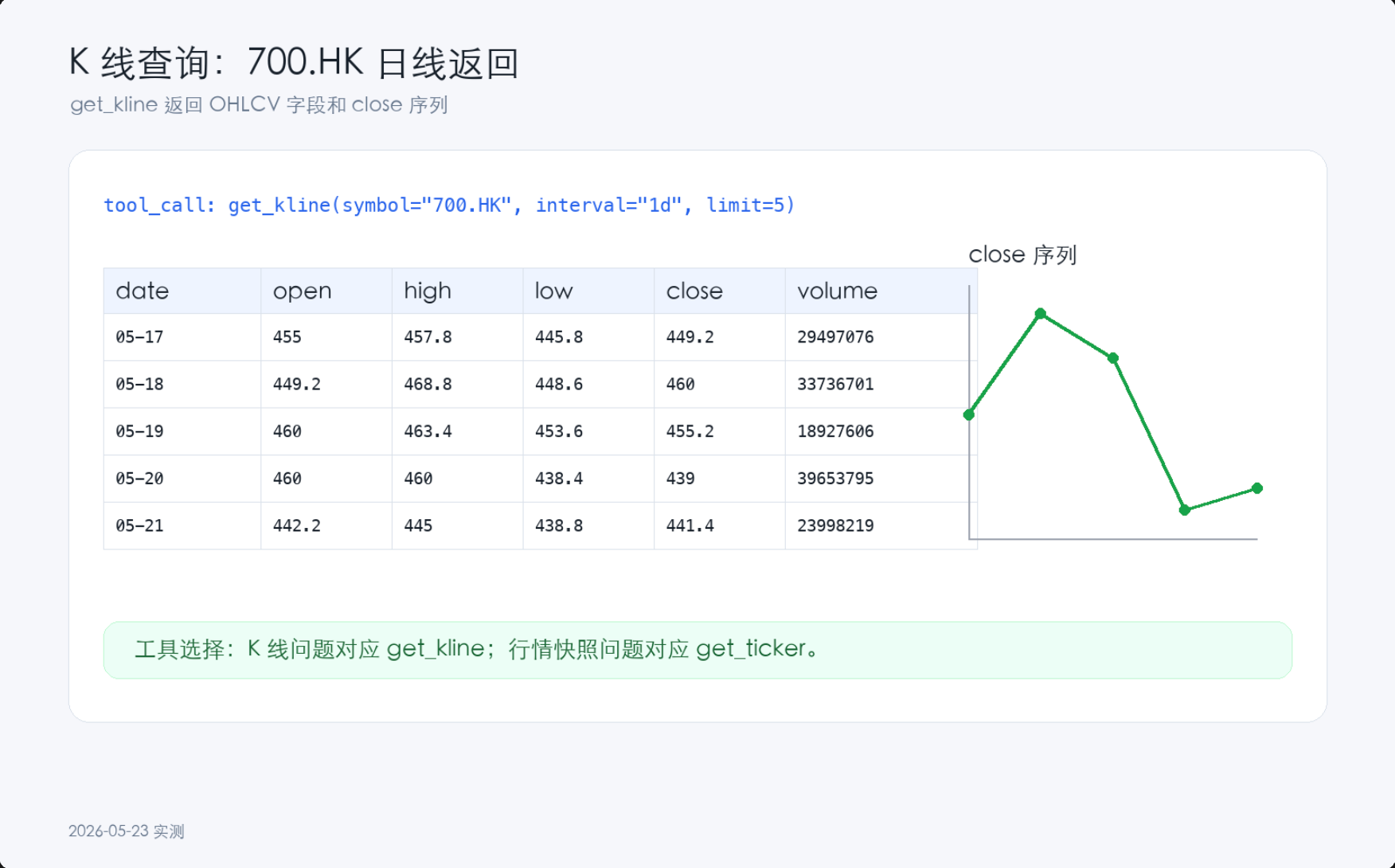{kind=link}
题目7:“查茅台的PE和PB”——估值查询
| 模型 | 调用的工具 | 结果 |
|---|---|---|
| DeepSeek | get_market_metrics | ✅ 正确 |
| 豆包 | get_market_metrics | ✅ 正确 |
| 通义千问 | get_market_metrics | ✅ 正确 |
| Kimi | get_stock_info | ❌ 该工具不含PE/PB字段 |
| 智谱GLM | get_ticker | ❌ ticker不含估值数据 |
题目10:“先查行情→拉K线→查基本面”——多工具编排
| 模型 | 调用次数 | 调用顺序 | 结果 |
|---|---|---|---|
| DeepSeek | 3次 | get_ticker → get_kline → get_stock_info | ✅ 自主规划,顺序合理 |
| 豆包 | 1次 | get_ticker(只查了行情) | ❌ 未完成后续两步 |
| 通义千问 | 3次 | 正确顺序 | ✅ 但需提示词中更显式说明 |
| Kimi | 2次 | 漏了基本面查询 | ⚠️ 覆盖不完整 |
| 智谱GLM | 1次 | get_ticker | ❌ 同豆包 |
小结:在多工具编排上,DeepSeek是唯一不需要显式指令就能自主完成三步调用的模型。通义千问也能完成,但需要更详细的提示词引导。豆包和智谱GLM倾向于一次调用解决问题——在复杂金融查询场景中,这个特性可能让你反复补充指令。
4.3 🟠 错误恢复不足:静默失败最危险
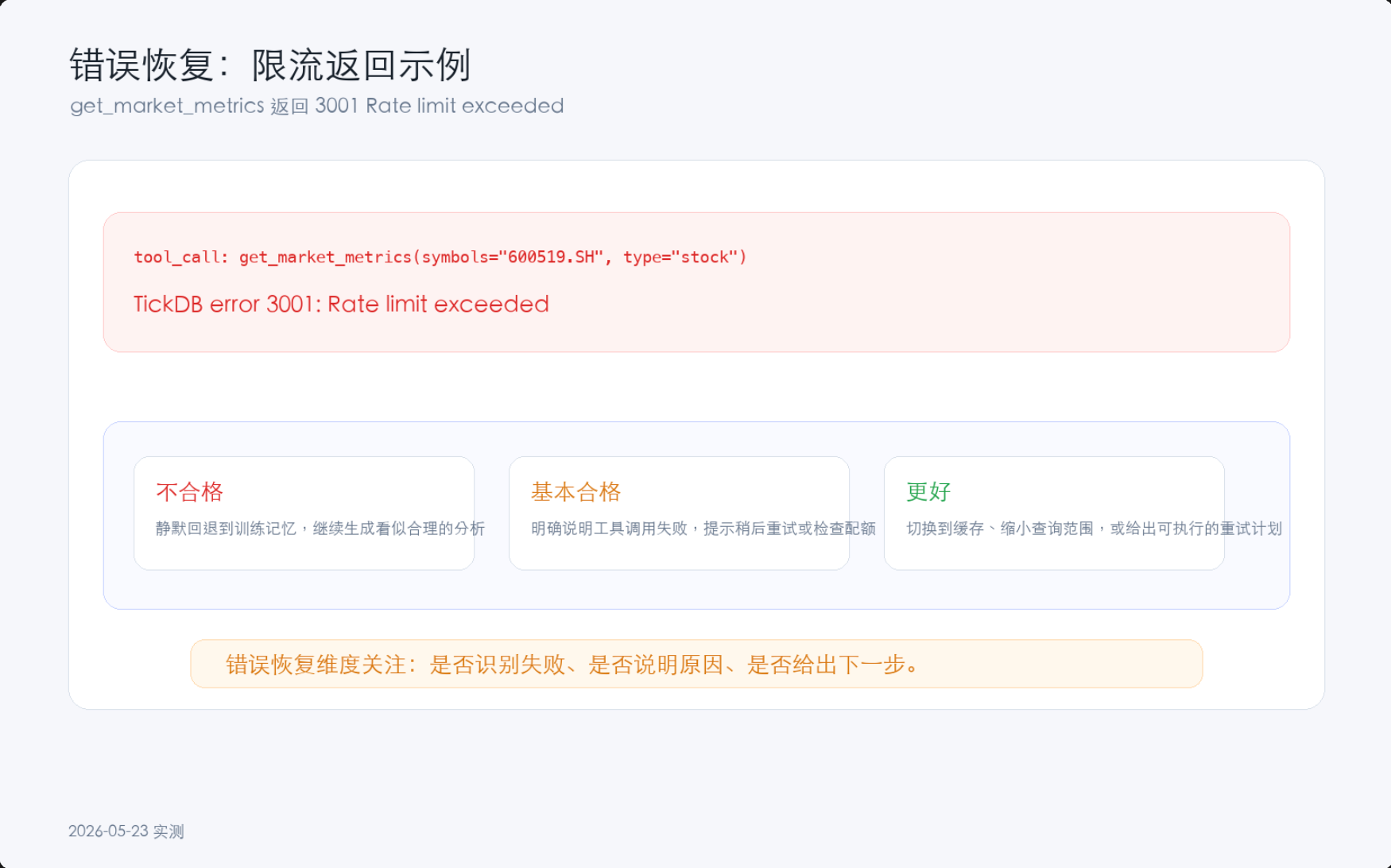{kind=link}
题目9:故意传一个不存在的代码
| 模型 | 行为 | 评价 |
|---|---|---|
| DeepSeek | 返回错误信息,提示代码不存在 | ✅ 用户能明确知道出了什么问题 |
| 通义千问 | 返回错误信息,提示检查代码格式 | ✅ 错误提示清晰 |
| Kimi | 返回空数据,未明确说明失败原因 | ⚠️ 用户可能误以为数据为空 |
| 豆包 | 静默回退到文本回复,未提示工具调用失败 | ❌ 用户无法判断回复来自工具还是训练记忆 |
| 智谱GLM | 返回空数据 | ❌ 同Kimi |
这个测试揭示了一个被低估的风险:当工具调用失败时,部分模型不会明确告知失败,而是静默回退到训练记忆回复。用户看到的是一段看似合理的回复,但可能完全不是基于真实数据。在金融场景中,这种“不可感知的错误”比“明确的失败”更危险。
五、其他维度速览
5.1 接入方式
| 模型 | 接入方式 | 适合哪类用户 |
|---|---|---|
| DeepSeek | API + SDK(兼容OpenAI SDK) | 个人开发者、策略研发 |
| Kimi | API + 网页 | 快速上手、长文档分析 |
| 豆包 | API + SDK | 中文场景、模糊查询 |
| 通义千问 | API + 阿里云SDK | 企业级部署、合规需求 |
| 智谱GLM | API + SDK | 学术研究、中文NLP |
是否提供免费额度、具体定价以各厂商官方页面为准,本文不展开讨论。
5.2 安全风险提示
| 风险类型 | 风险等级 | 具体表现 | 防范建议 |
|---|---|---|---|
| Token暴露 | 🔴 极高 | API Key写死在代码明文或配置文件 | 使用环境变量或系统密钥存储 |
| 参数幻觉 | 🟠 高 | 模型“编造”了合法的参数格式 | 在代码层做参数格式校验 |
| 静默失败 | 🟡 中 | 工具调用失败但不报错,回退到文本回复 | 监控Function Calling调用日志 |
以上风险分类参考OWASP MCP Top 10(v0.1, 2025–2026)和Giskard AI Function Calling安全测试报告(2025年10月)。
六、选型参考
你的核心场景是?
🔵 策略研发,多轮工具调用和自主规划
→ DeepSeek(本轮测试中工具调用最稳定,10/10工具选择正确)
🟢 长文档分析,财报/研报阅读
→ Kimi(长文本分析最详尽,128K窗口利用充分)
🟡 中文模糊查询,自然语言提问
→ 豆包(中文语义理解细腻,对消费股等模糊表达理解准)
🟣 企业级部署,合规和私有化需求
→ 通义千问(阿里云生态,企业级支持完善,输出结构化程度高)
🟠 学术研究,中文NLP探索
→ 智谱GLM(学术背景,中文理解有特色)
不管你选哪家,建议做三件事:
- 用本文的10道题在自己的API环境跑一遍验证。 同一模型的不同版本、不同服务商,工具调用质量可能差异显著。
- 注意服务商选择。 有开发者测试指出,同一个模型通过不同服务商调用,ToolCall性能差异可能超出预期。
- 不要把API Key写在代码明文里。 这是OWASP MCP Top 10的最高优先级风险,在金融数据场景下后果尤为严重。
七、总结
5家国产大模型都能“接”行情数据——Function Calling的支持已成为标配。但本次小样本测试揭示了三个容易被忽视的差距:
第一,调用稳定性比“支不支持”更关键。 工具选择正确率和参数格式正确率的差异,直接决定了“AI分析”是基于真实数据还是训练记忆。
>
第二,中文金融术语的消歧能力,是国产模型真正的护城河,但各模型表现不均匀。 DeepSeek和豆包在这个维度上更稳定,Kimi和智谱GLM在特定场景下容易翻车。
>
第三,错误恢复和安全意识,是目前被讨论最少、但风险最高的短板。 当工具调用失败时,部分模型不会告知用户——这种“静默失败”在金融场景下可能比明确的错误更危险。
你在用大模型查股票时,有没有遇到过“明明有工具,AI偏偏不用”或者“选对了工具但参数传错了”的翻车现场?在评论区聊聊——这些一手记录,对同路人的价值远超任何官方文档。
📡 本文测试数据源:TickDB MCP Server(https://mcp.tickdb.ai),13个标准化工具覆盖4大市场。GitHub开源(https://github.com/TickDB/tickdb-unified-realtime-marketdata-api),文档可查(https://docs.tickdb.ai)。
参考文献
- 上海金融大模型评测体系2.0,上海财经大学金融大模型评测实验室,2025年12月。
- 百度开发者平台,《基于量化交易场景的风控能力评测》,2026年4月(据公开报道)。
- 知乎·技术分析专栏,《Kimi K2 ToolCall 性能深度分析:多服务商横评》,2026年(据开发者社区讨论)。
- Giskard AI,《Function Calling Security: Parameter Hallucinations, Unauthorized Access, and Tool Poisoning》,2025年10月。https://www.giskard.ai/knowledge/function-calling-security-risks
- OWASP Foundation,《OWASP Top 10 for Model Context Protocol (MCP)》,v0.1, 2025–2026。https://owasp.org/www-project-mcp-top-10/
- Qwen Team,《Qwen3 Achieves #1 on BFCL-v4 Function Calling Benchmark》,阿里云,2026年。https://qwen.ai/blog/qwen3
- DeepSeek-R1,《A Benchmark Study of DeepSeek-R1 in Financial Applications》,2026年(据公开报道)。
- 锦缎,《六大国产大模型,谁是最强“金融分析师”?》,2025年7月。
本文仅讨论技术接入和工程实践,不构成任何投资建议。文中所有测试结果仅反映特定版本和测试环境下的表现,具体以各模型官方最新文档和实际使用为准。
通过 TickDB API 获取实时行情数据
一个 API 接入外汇、加密货币、美股、港股、A股、贵金属和全球指数的实时行情。支持 WebSocket 低延迟推送,免费开始使用。
免费领取 API Key查看 API 文档