A股实时行情接口怎么选?从免费开源到生产级API——mootdx、Tushare、TickDB、Wind 6家数据源底层对比与验证指南
作者: TickDB Research · 发布: 2026/6/23 · 阅读: 12
标签: F13, 知乎/A002
摘要:面对mootdx、akshare、TickDB、Tushare Pro、同花顺热点和Wind这6家A股实时行情数据源,选型的真正难题不是“谁最好”,而是“哪个在我的场景里最扛得住”。本文把6个方案从协议层、返回形式、字段校准、异常容错到隐性成本拆解到底层,给出一份你能立刻复现的5步验证清单。
选数据源这件事,有一种“推荐文陷阱”:每篇都把各家优点列一遍,看完觉得收获满满,合上文章却仍然不知道自己的脚本明天会不会在开盘时崩掉。
因为你读到的那些维度——全面、稳定、低延迟——都不是你能验证的。你不能验证的结论,就是别人的结论。
所以本文换一种做法:把6家主流方案按5个能直接操作的底层维度拆开,每拆一层都附带一个你能跑的测试。等你用自己的股票代码跑完,你自己的系统会告诉你该选谁。
6家方案速览
| 方案 | 一句话定位 | 最适合谁 |
|---|---|---|
| mootdx | TCP直连通达信,免费实时行情的硬核工具 | 有国内服务器、能自己处理复权的技术流开发者 |
| akshare | 覆盖面最广的免费Python库,几乎所有公开财经数据它都试着收进来 | 学生、研究员、快速验证想法的探索阶段 |
| TickDB | 程序化实时行情API,为开发者和AI工具链设计的结构化数据通道 | 接系统、接Agent、接监控面板的开发者和小团队 |
| Tushare Pro | 研究型数据平台,提供经初步清洗的结构化数据 | 做A股量化回测的个人研究者 |
| 同花顺热点 | 零鉴权的题材归因信号,信息密度极高 | 做事件驱动策略、想快速感知当日题材的短线研究者 |
| Wind | 机构级金融终端的代名词,数据深度和治理水平是行业基准 | 持牌机构、对数据合规和权威性有硬要求的团队 |
维度1:协议层——数据怎么到你手上
是什么
协议层指的是数据从服务端传递到你代码里的通信方式。主流行情数据协议有三种:HTTP请求-响应(你主动去拉)、TCP长连接(建立连接后持续传输)、WebSocket推送(服务端主动推给你)。
为什么它决定了稳定性的天花板
三种协议的核心差异是“拉”和“推”。HTTP轮询的延迟由轮询间隔决定,且每次请求都要完整走一遍网络握手,高频调用容易触发反爬。TCP长连接绕过了应用层反爬,但协议一旦被服务端变更,客户端就必须跟着改。WebSocket推送从物理上消除了轮询开销,数据到达最快,但客户端需要自己处理断线重连和心跳。
怎么判断
看文档里“获取实时行情”的方式:需要反复调用同一个函数,底层是HTTP轮询;需要先建立连接再持续读取,底层是TCP或WebSocket。如果文档没写清楚接入方式,这本身就是一个信号。
| 方案 | 数据通路 | 协议层对稳定性的决定因素 |
|---|---|---|
| mootdx | TCP二进制直连通达信服务器群 | 不受HTTP反爬影响;但通达信协议一旦变更,整个库可能停摆,且强依赖国内IP |
| akshare | HTTP爬虫,底层抓取东财/新浪等网页 | 覆盖面广的代价是反爬风险高:45%请求打向东财,接口今天能用明天可能报错 |
| TickDB | RESTful快照 + WebSocket推送 | 推送模式从协议层保证实时性,数据不是“去要”而是“被推过来” |
| Tushare Pro | HTTP SDK,自有数据服务 | 比纯爬虫稳,但曾有服务中断记录,且旧接口在新版pandas下直接崩溃 |
| 同花顺热点 | HTTP,零鉴权 | 不需要Key,但接口随时可能被限制访问;盘后数据才完整 |
| Wind | SDK封装,私有协议 | 商业合同保障,但你的代码从第一天起就绑定Wind SDK |
你能立刻做的测试:不写代码。打开候选方案的文档,找到“获取实时行情”的说明。如果它让你调一个封装好的函数,网络层已被处理好。如果它让你自己构造HTTP请求,你还要写重试、超时、断连恢复——这些与业务无关,却是生产系统里最容易出问题的地方。
维度2:返回形式——数据到你手上时长什么样
是什么
返回形式指的是你的代码调用接口后拿到的原始数据形态。常见的三种:结构化数据(JSON/DataFrame)、半结构化文本(用分隔符连接的字符串)、非结构化内容(HTML/混杂文本)。
为什么它决定了代码复杂度
解析代码是技术债的高发区。一段处理分隔符文本的解析逻辑,在标准情况下工作正常,但遇到某只股票停牌、字段为空或上游网站加了新字段时,就可能因为索引偏移而拿到错误数据。
更深远的影响是AI兼容性。如果你的系统未来要接入AI Agent,接口返回的数据必须能被Agent的函数调用机制直接消费——也就是纯净的JSON。如果返回的是分隔符文本,Agent需要额外的解析步骤,每次额外调用都增加延迟和失败概率。
{kind=link}
怎么判断
把原始返回直接print出来,看它能不能被一行代码消费。能直接json.loads()的是满分;需要用split()按分隔符拆开再按索引取值的,每多一个步骤就多一层出错可能。
| 方案 | 返回形态 | 你的代码要额外做什么 |
|---|---|---|
| mootdx | pandas DataFrame | 需处理datetime字段双重存在(同时出现在index和column中) |
| akshare | 多数返回DataFrame,部分接口返回dict/HTML | 接口间不统一,调用前要查Issue确认当前状态 |
| TickDB | 纯净结构化JSON | 几乎不需要额外解析,可直接注册为LLM Function Calling工具 |
| Tushare Pro | pandas DataFrame,字段规整 | 相对少,旧接口在pandas 2.x下需迁移 |
| 同花顺热点 | JSON,字段名errocode有拼写错误 | 适配一下字段名即可 |
| Wind | SDK内已封装 | SDK内已处理,但Agent调用需经过SDK中转 |
一个社区已经验证的公开案例:腾讯财经的行情接口,字段索引43被国内大量教程标为“PB(市净率)”,社区实测发现真正的PB在索引46,索引43是振幅。这就是“按索引取分隔符文本”这种返回形式的固有风险——字段位置一变,你的代码悄无声息地拿到错误数据。
你能立刻做的测试:调一次接口,把返回结果直接print出来。如果是{"symbol":"600519.SH","last_price":1850.00},你的Agent就能直接消费。如果是var hq_str_sh600519="开头的一长串,你需要写一个解析模块。
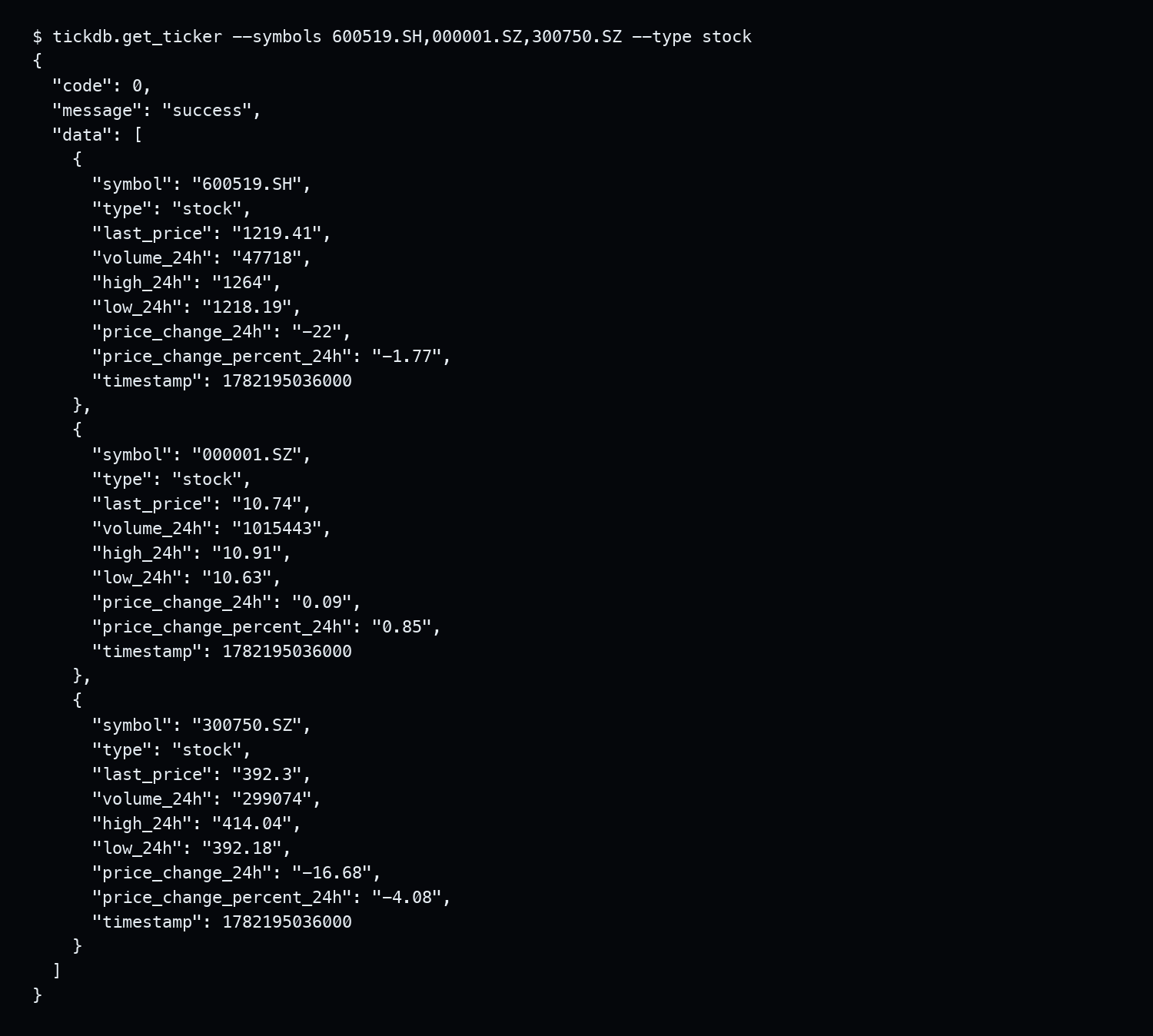{kind=link}
实测:通过 tickdb.get_ticker 工具直接调用 600519.SH、000001.SZ、300750.SZ 的 A 股实时行情,返回结构化 JSON,可直接用于程序化处理。
维度3:字段校准——同一只股票跑出来的数据对得上吗
是什么
字段校准指的是用同一个股票代码、在同一个时刻,向不同数据源发起查询,然后逐字段比对返回结果。这不是比“谁快谁慢”,而是检查更基本的问题:不同源给出的last_price是同一个价格吗?volume用的是同一个单位吗?
为什么字段校准是选型的必做项
不同数据源对同一个字段的口径、单位、时间基准可能完全不同。这不是bug,而是每个源有自己的数据处理管线。如果你只接一个源,永远不会发现这种差异——等回测中发现异常时,已经跑了两个月的数据。
字段差异有三个来源:时间基准不同(交易所时间 vs 服务器时间)、单位不一致(股 vs 手,差100倍)、复权处理管线不同(原始价格 vs 前复权 vs 后复权)。
怎么拆解
选一只你熟悉的股票(600519.SH),对候选源做6个校准点的核对:
| 校准点 | 为什么重要 | 真实发生过的坑 |
|---|---|---|
| symbol格式 | 你的系统里是600519.SH,源返回600519.XSHG,if symbol ==判断全挂 | 不同源的上市场所后缀规则不同 |
| last_price | 最新价是行情的基准,错一个点,后面全错 | 有些源在集合竞价时段返回0或昨收 |
| timestamp | 策略信号需要知道“这个价格是几点的” | 有的源给交易所时间,有的给服务器时间 |
| volume单位 | 成交量量纲是手还是股 | 把“手”当“股”用,成交量放大100倍 |
| pre_close | 涨跌幅计算的基准 | 复权处理不当,昨收被修改,涨跌幅全歪 |
| 非交易时段返回体 | 监控脚本半夜会不会误报警 | 收盘后返回500或假数据 |
你能立刻做的测试:选两个候选源,用同一只股票(600519.SH)各调一次,对比last_price和volume。如果对不上,至少一个源需要校准——这个发现,在你用它跑回测之前解决,成本为零。
维度4:异常容错——不该出错的时候它怎么表现
是什么
异常容错指的是数据源在非标准情况下返回什么:交易时段外、调用频率超限、标的停牌、网络闪断。所有方案的文档都会写“高可用”,但在这些边界场景下真正返回什么,只有跑过才知道。
为什么这个维度容易被忽略
因为测试通常在交易时段进行。你第一次调接口是在某个工作日的上午10点,一切正常。上线后第一个周末,监控脚本凌晨报警——数据源在非交易时段返回了HTTP 500。这种问题在测试阶段遇不到,但一上线就变成每周两天的噪音。
异常容错能力取决于两个因素:一是服务端对“无数据”的定义方式(干净的做法是返回200+空data,粗糙的做法是返回500或超时);二是限流机制的透明度(是否通过429状态码和Retry-After头告诉你要等多久)。
| 异常场景 | 干净的表现 | 危险的表现 |
|---|---|---|
| 交易时段外调用 | HTTP 200 + 空data或明确“非交易时段” | HTTP 500 / 返回收盘价的假数据 |
| 调用频率超限 | HTTP 429 + Retry-After头 | 直接封IP / 返回空数据 / 无任何提示 |
| 某只股票停牌 | last_price保持停牌前价格,volume为0 | 字段消失 / 返回一个0.0001的垃圾值 |
| 网络闪断后恢复 | 自动重连,历史数据补推 | 需要手动重启,中间数据永久缺失 |
你能立刻做的测试:收盘后(15:30之后)调一次接口。如果返回报错或HTML乱码,你的系统就需要加一个“非交易时段判断”逻辑。如果返回200加空data,这一步就可以省略。
维度5:隐性成本——免费背后的真实账单
是什么
隐性成本指的是选型时没有写在预算表里、但未来一定会付出的代价。它不一定是货币,更多是时间、精力和系统在关键时刻挂掉带来的机会成本。
为什么只看显性价格会做出错误决策
免费源的逻辑是:你不用付钱,但要自己承担维护成本。上游网站改版、反爬升级、接口失效时,修复的责任在你。付费源的逻辑是:你付的钱买的是“确定性”——知道这个接口明天还能用,出问题有人负责,返回格式不会悄无声息地变。
把时间换算成成本。如果每小时时间值200元,每个月花2小时修数据源,一年就是4800元隐性成本,可能已超过一个付费方案的年费。你自己的场景决定了这个时间成本是多少。
| 方案 | 显性成本 | 你付出的时间 | 你最容易低估的 |
|---|---|---|---|
| mootdx | 免费 | 需自己写复权逻辑;需国内网络环境 | 通达信协议变更时你没有应对方案 |
| akshare | 免费 | 接口失效后的排查和等待修复 | 它在最关键的时刻挂掉,成本不是零是负 |
| TickDB | 有免费体验期,付费前可充分验证 | 接入即用,解析成本极低 | 免费体验的目的是让你在正式用之前完成本文这5项验证 |
| Tushare Pro | 积分/付费 | 积分获取需精力投入;核心数据在积分墙后 | 服务中断带来的迁移成本 |
| 同花顺热点 | 免费 | 接口随时可能被限制访问 | 盘后数据才完整,盘中调用不稳定 |
| Wind | 机构级定价 | 学习SDK和申请流程 | 供应商锁定:写得越多,换的代价越大 |
关于免费和付费的选择逻辑:免费源的隐形成本是你未来要付的时间,而且这个时间是随机的,最可能在你最需要它的时候发生。如果你只是学习验证,这个成本可以接受。如果你要跑生产、接系统,你要的是确定性。用体验期,就是为了在决定之前用自己的symbol跑完验证,确认这个确定性是否存在。
你的场景该重点看哪几个维度
| 你的场景 | 最关键的维度(按优先级) | 可以适当放宽的 |
|---|---|---|
| 学习验证、跑课程项目 | 返回形式 > 成本 | 协议层、异常容错 |
| 个人量化回测 | 字段校准 > 隐性成本 > 返回形式 | 异常时段表现 |
| 生产级实时系统 | 协议层 > 异常容错 > 字段校准 | 成本(稳定是第一优先级) |
| 给AI Agent接数据 | 返回形式 > 协议层 > 字段校准 | 成本 |
| 小团队既要研究又要生产 | 协议层 + 返回形式 + 字段校准全要看 | 无 |
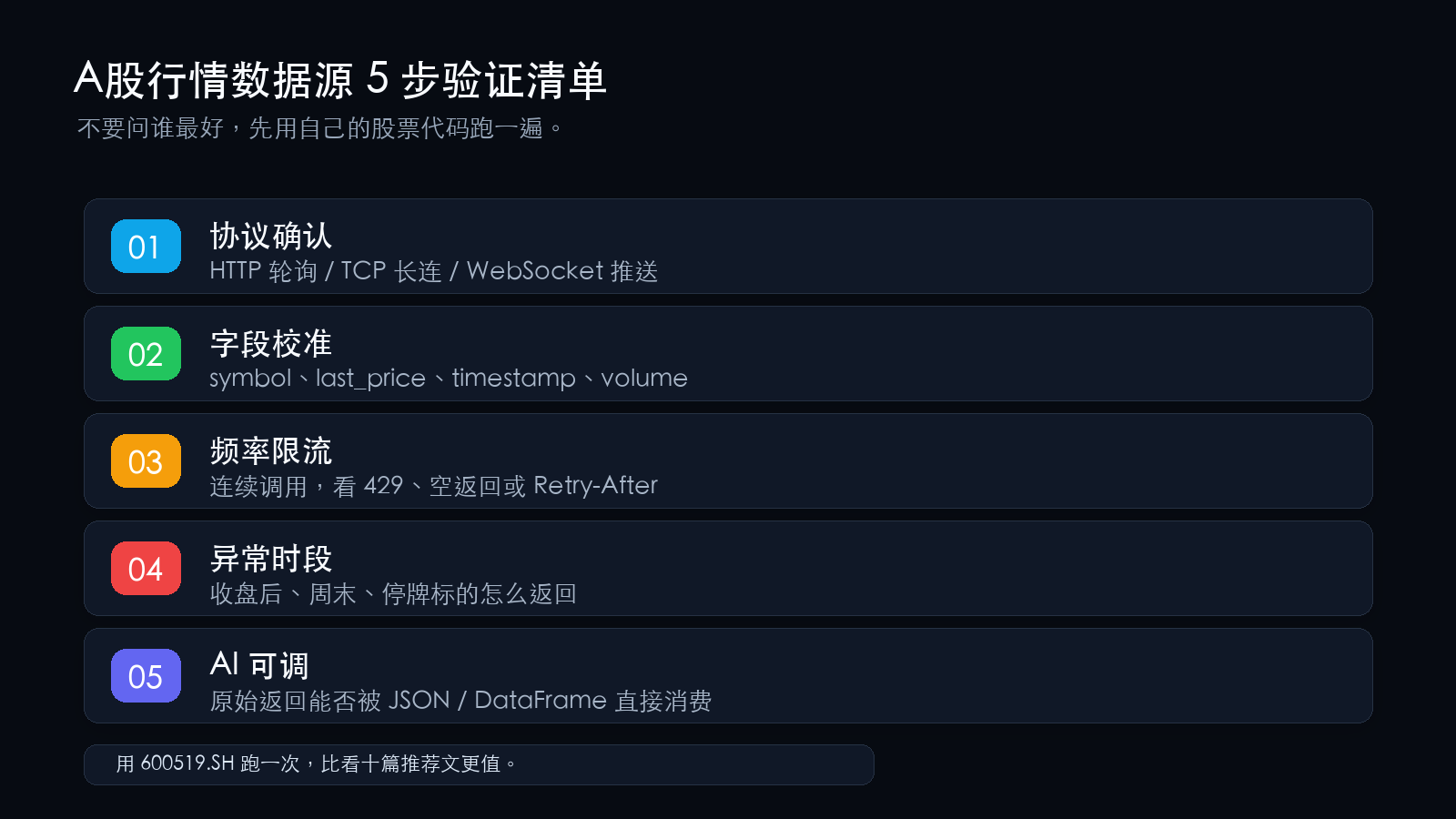
一张你就能跑起来的验证清单
选一个你正在评估的方案,按顺序跑这5步:
| 验证项 | 操作 | 过了的标志 | 没过说明什么 |
|---|---|---|---|
| ① 协议确认 | 看文档,确认数据是HTTP轮询、TCP直连还是WebSocket推送 | 协议类型与你的场景匹配 | 生产系统选了HTTP爬虫,凌晨挂掉是早晚的事 |
| ② 字段校准 | 用600519.SH调一次,检查symbol、last_price、timestamp、volume、pre_close | 6个字段全正常,数值合理 | 数据通路有坑,不能直接上生产 |
| ③ 频率限流 | 连续调10次,看有无429或空返回 | 无限流,或限流规则透明(有Retry-After) | 你的调用量会被掐,需要加缓存层 |
| ④ 异常时段 | 收盘后和周末各调一次 | 返回200 + 空data或明确“非交易时段” | 你的监控系统需要加特殊处理 |
| ⑤ AI可调 | 看原始返回体是否是纯净JSON或DataFrame | json.loads(response)成功,无额外文本 | Agent没法直接用,需要额外写解析层 |
跑完怎么办:5项全部“过”的方案,可以在你的场景里进入下一轮评估。有“没过”的,不是方案不行,是它和你的需求不匹配。
{kind=link}
选型这件事,最值的30分钟,不是你读推荐文的那30分钟,而是你用自己的数据跑验证的那30分钟。
通过 TickDB API 获取实时行情数据
一个 API 接入外汇、加密货币、美股、港股、A股、贵金属和全球指数的实时行情。支持 WebSocket 低延迟推送,免费开始使用。
免费领取 API Key查看 API 文档