Kimi、豆包、DeepSeek聊股票的底层机制:为什么AI分析再流畅,也不能绕过实时行情数据
作者: TickDB Research · 发布: 2026/6/25 · 阅读: 6
标签: T25-01, 知乎 / A005
摘要:Kimi能读财报,豆包能聊行业,DeepSeek能写策略代码,问财能查个股基本面——它们聊起股票来越来越像专家。但如果你追问一句“刚才那条行情数据几点几分、从哪来的”,大多数工具会在这道追问前沉默。这篇文章不评测、不排名,只拆解AI金融工具背后的数据获取机制:为什么静态模型和动态行情之间存在结构性矛盾?为什么“查不到数据时编一个”比报错更危险?以及,为什么绕过实时行情数据的AI分析,从一开始就缺少一个可以被复核的地基。
你有没有过这种体验:AI给出一段股票分析,读起来逻辑严密、措辞专业,你下意识就觉得“有道理”。但如果逐条去核它引用的数据,可能会发现至少有一条是错的。
AI的语气说服了我们,但数据没有被验证。
这不止是技术问题,更是我们人类的认知习惯——对流畅表达天然放低戒备。研究者管这叫自动化偏差:当输出足够通顺时,我们会不自觉地跳过质疑。在金融这个对数据真实性有极致要求的领域,这个习惯可能是最贵的。
你用Kimi读过财报,用豆包问过行业,用DeepSeek跑过回测代码,用问财查过个股基本面。它们聊起股票来,一个比一个像模像样。但如果你追问一句:“你刚才用的那条行情数据,几点几分、从哪个数据源来的?”
大多数工具会在这个问题上沉默。
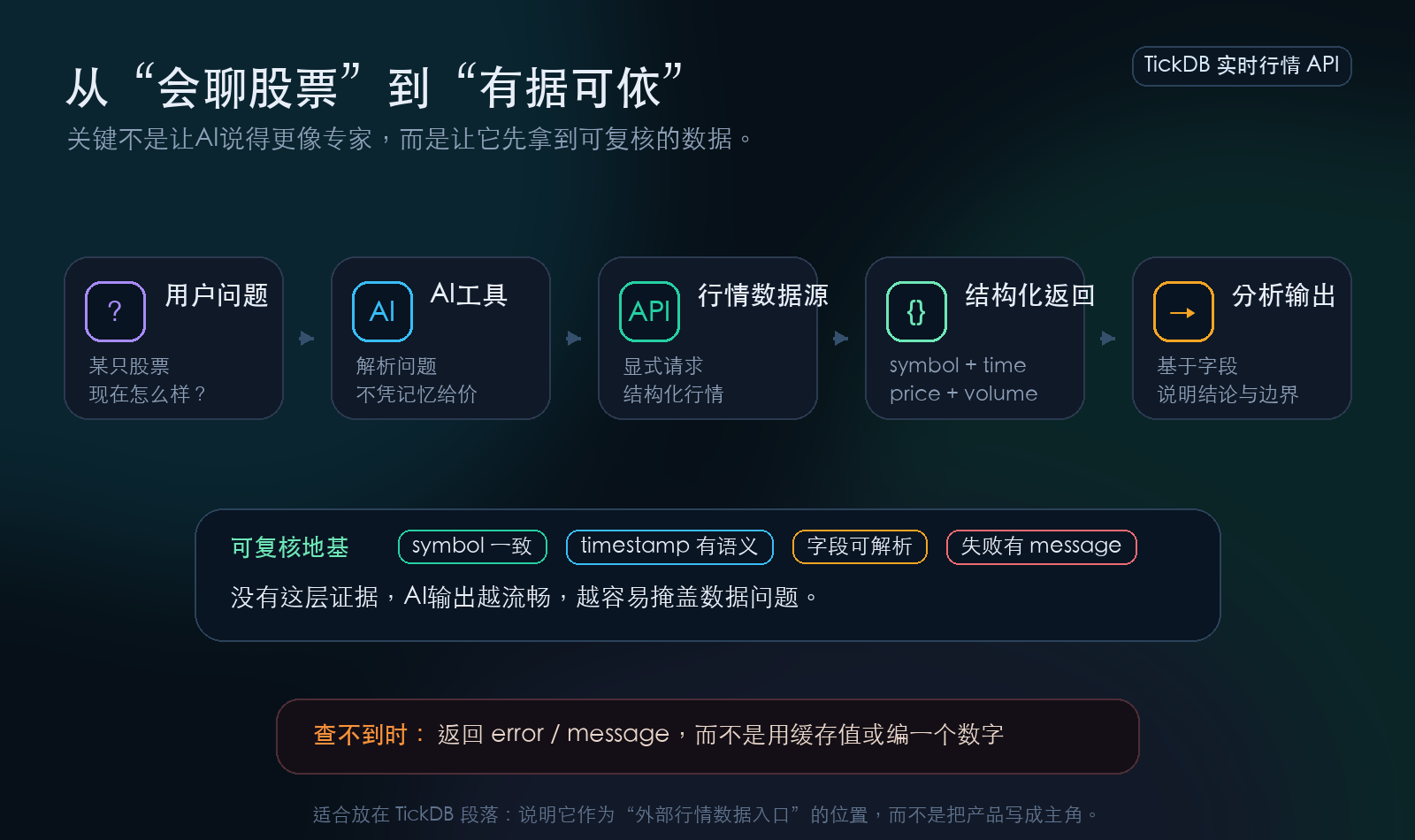
能聊股票,不等于真的在看盘。差别在哪,下面一步步拆开。
一、AI聊股票的四种方式
市面上的AI金融工具,按数据获取方式可以分成四类。分析能力有高有低,但数据入口的天花板从一开始就不一样。
第一类:通用大模型助手。 Kimi、豆包、通义千问、DeepSeek。它们的数据来源是训练语料、联网搜索和用户上传的文件。聊股票时,本质上是在做文本工作——把财经新闻浓缩成要点,把财报数字摘出来,把宏观逻辑用流畅中文讲清楚。这些事做得很好,但都不需要当前行情数据。
当你问它“现在某只股票多少钱”,它如果从训练记忆里拿,给的可能是几个月前的价;从搜索结果拿,抓到的可能是某财经网站缓存下来的、半小时前的页面。它不会告诉你这个数字已经过期了。
第二类:金融问答与资讯工具。 以问财为代表,背后接了一个内置金融数据库,把财务指标、公告、新闻和基础行情打包呈现。查“近三年净利润增速”这类事实型数据体验很好,但涉及当前盘口的实时价格和成交量时,更新频率和覆盖范围往往不透明,而且数据通常无法被外部程序调用。
第三类:专业金融终端。 Wind、iFinD等,机构研究员的日常工具。数据质量和覆盖深度经过市场检验,但采购门槛高,AI分析层与终端深度绑定,外部工具难以直接调用。
第四类:开发者与Agent工具链。 Cursor、Claude Code、Coze、Dify。目前最活跃的AI开发工具,但它们本身不带任何行情数据。接了什么数据源,AI就看到什么。 接得好是利器,接得不好就是在黑暗中流畅地胡说。
{kind=link}
没有一种工具适合所有人。普通用户看财报、读公告,通用大模型够用。个股研究者查基本面,金融问答工具更趁手。机构研究员需要专业终端。而如果你是开发者、量化研究员或金融应用团队,核心问题就不再是“用哪个App”,而是“我的AI工具能调用哪个行情数据源”。
二、五问之下,谁能回答
不管用哪一类工具,有一套判断框架可以帮你快速分辨它是不是真的在看盘。这不是给厂商打分的标准,而是给你自己用的检查清单。
第一问:数据从哪来?
这是根源问题。当AI给一个价格、一个涨跌幅时,追问一句:这个数字是从哪里来的?
是实时行情数据源的API返回?是内置数据库里的一条记录?还是搜索引擎从某个财经网站上抓到的网页文本?三者天壤之别。API返回的是结构化、带字段定义、可解析的数据。数据库记录有明确的更新机制。而网页文本——就算那个网页上恰好显示着一只股票的价格——AI拿到的只是一段去语境化的文字。价格数字可能和股票代码不在同一个HTML节点里,可能是几小时前的缓存。用网页文本做行情分析,是在流沙上盖房子。
更隐蔽的风险在后面。
我见过一个案例:盘后查某只股票,接口返回了空数据。正常来说该告诉用户“没查到”。但AI没有——它用上一次成功查询的缓存值填上去,没做任何说明。用户看了三天“最新价”,实际是三天前的收盘价。
技术圈给这类问题起了个名字,叫静默失败——失败了,但不说。金融上很多重大事故,起点不是数据缺失,是数据错了没人知道。
剑桥大学一份覆盖全球151个国家的行业调研提供了一个参照:金融行业已有40%处于AI先进应用阶段,而监管机构这一比例只有20%。行业跑得比监管快,意味着在规则完全到位之前,我们自己得先有一双辨认数据真伪的眼睛。
第二问:标的是否确认?
“某龙头白酒”是一句中文,“600xxx”是一个代码。在金融数据系统里,AI必须确认标的的准确代码,再去查数据,而不是在两个概念之间跳来跳去。
验证方法很简单:问它“请确认你要查询的标的代码”。如果它给出“600xxx”并明确市场后缀(如.SH),说明它在做结构化查询。如果它只反复说公司名而不给代码,或者给的代码和你理解的市场不一致——它大概率没有真的去查行情接口,而是在做文本联想。
请求和响应里的symbol必须逐字符一致。任何静默修正,都是未来排查时的定时炸弹。
第三问:时间是什么时候?
行情数据的价值,从它被生成的那一刻起就在迅速衰减。三秒前的盘口价和三小时前的快照,是两个世界。
这不止是“数据延迟”的问题,而是静态训练数据和动态市场之间的结构性矛盾——有研究者管这叫动态数据衰减。AI用静态数据训练,但金融信息是极速失效的动态数据。这个矛盾不是bug,是模型和市场的基因冲突。
所以追问时间戳时,不但要问“是哪天”,还要问:这个时间是行情发生的时刻,还是服务端处理数据的时刻,还是AI拿到数据的时刻?有没有时区标注?A股是东八区,美股是美东时间,加密市场用UTC。不带时区的行情数据,跨市场对比时会把不同时间线上的数据硬拼在一起——结论从一开始就歪了。
第四问:字段能不能解析?
行情数据不是一句话描述,而是一张多字段的快照表。最新价告诉你此刻成交在什么价位。成交量告诉你这个价位上发生了多少换手。最高最低告诉你今天的波动区间。昨收告诉你今天是从哪起步的。
如果你的AI工具只说“这只股票目前在某个价位附近震荡”,而不给可解析的数字字段——没精确价格、没量、没涨跌幅——你拿到的不是行情数据,是行情散文。散文可以读,但不能算。
数字字段有值就给数字,没值就显式给null,绝不出现非数字占位字符串。结构的一致性,比有没有值更重要。
第五问:查不到的时候会不会编答案?
这环最容易出问题。你问一个不存在的代码、不在交易时段的品种,或者查询因为超时没返回结果——AI会怎么处理?
语言模型有“填空”的本能。当它拿不到数据时,它可能根据上下文编造一个听起来合理的数字,甚至不会主动告诉你“这个数据查不到”。又回到了第一问提到的问题:静默失败。
失败不可怕,掩盖失败才可怕。一个合格的数据处理链路,在查不到、超时、无权限、非交易时段等异常情况下,应该返回明确的失败信息,而不是静默降级或编造替代值。
{kind=link}
三、如果你想更进一步
读财报、解读政策、总结新闻,通用AI助手已经够用。但如果你的需求是让AI先查一份真实、结构化、带时间戳的行情数据,再开口分析——那就需要外部行情数据源了。
这是从“AI会聊股票”到“AI真的有据可依”的关键一步。
{kind=link}
TickDB 就是为这个需求设计的外部行情数据入口之一。它不是“AI选股工具”,不帮你判断买卖点,也不预测涨跌。它做的事很聚焦:提供一份能被AI工具调用的真实行情数据,让symbol、timestamp和结构化字段在你提问之前先落地。
对照上面五问检查法,TickDB在各环节的表现如下:
数据来源:独立外部行情接口,通过REST API提供数据。AI工具可通过函数调用显式发起请求,而非凭模型记忆或搜索结果猜测。查不到时返回结构化错误信息,而不是静默填值。
Symbol匹配:请求一个具体代码(如“600xxx”),返回的data.symbol原样返回,不自动追加后缀或静默修正。
Timestamp语义:时间戳字段带+08:00时区标注,与tradeDate对应,可追溯到交易所行情生成的时刻。
字段结构:最新价、成交量、开盘、最高最低、涨跌幅等均为JSON number,类型恒定,不出现非数字占位符。
失败分支:无效symbol或Token错误时返回code非零和可解析的message字段,能被日志系统直接结构化处理。
这几项不是“通过检查”的终点,而是你用自己的symbol亲手跑一遍之后,可以留存的证据快照。下次换数据源、升级版本、甚至凌晨巡检时翻出来看一眼,都能知道当初信任它的时候,它到底交回了什么。
另外,对于准备将数据源接入生产环境的开发者,五问验证通过只是单次调用的快照。后续还有三件事不能省:多数据源交叉验证(不同时段、不同品种、不同市场状态下的返回一致性)、异常行情日回放(用历史波动剧烈交易日的录包数据回灌测试)、以及长时间推量测试(验证延迟和可用性在持续压力下的表现)。这些不是第一次评估就要做的,但它们是生产环境上线前绕不开的。
TickDB不是唯一选择。它是一个面向“可验证”这个标准设计的数据入口。具体端点、配置方式和Header写法,以官方文档和你自己的测试结果为准。
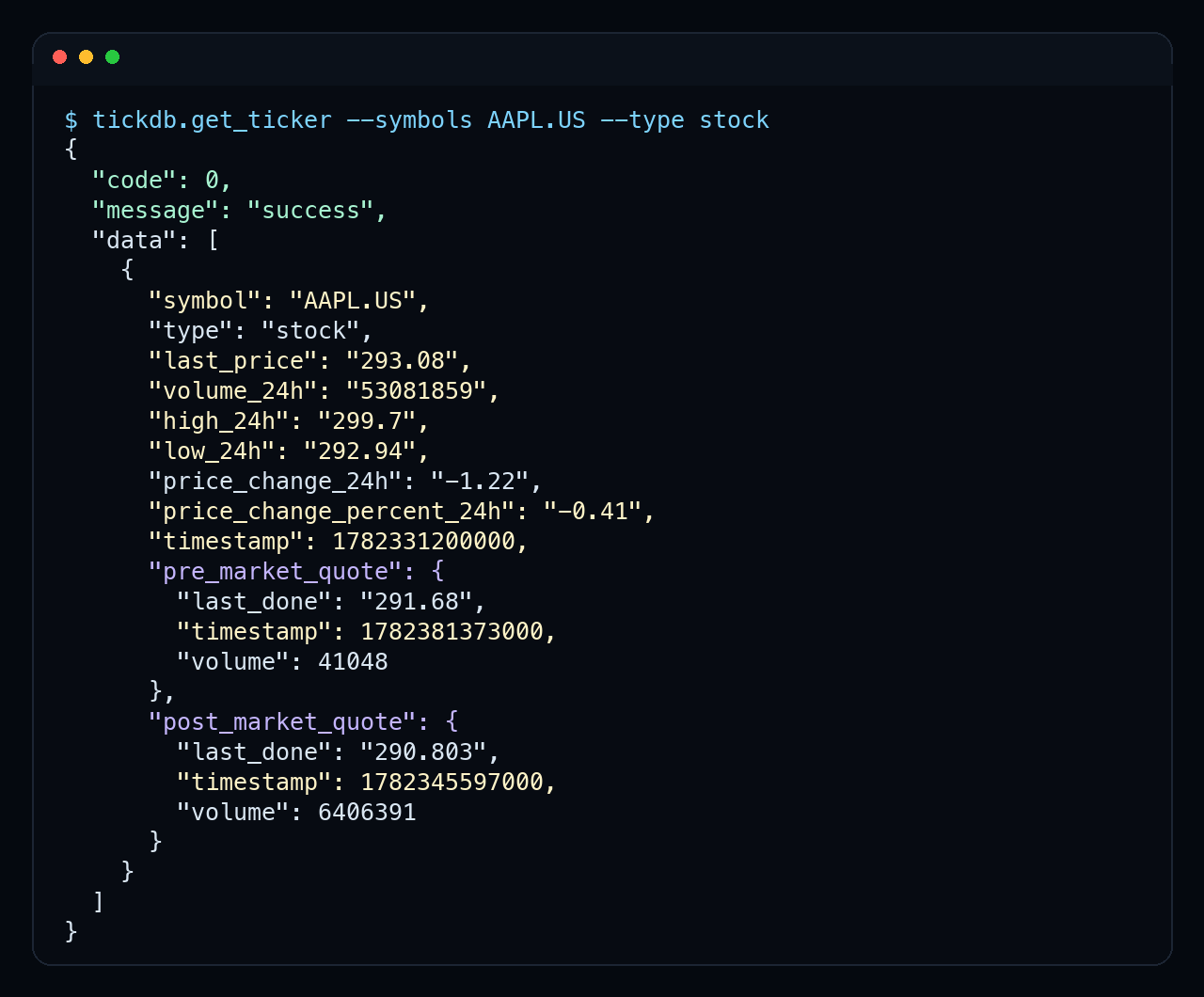{kind=link}
实测:通过 tickdb.get_ticker 查询 AAPL.US 行情,返回 symbol、last_price、volume_24h、timestamp 等结构化字段。此处仅展示一次真实字段返回,不构成投资建议。
四、适合谁,不适合谁
有真实行情数据入口的AI工具链,适合做:跨市场行情快速查询,辅助研究时获取当前数据快照;写研究脚本时提供可复现、可追溯的数据输入;帮助验证数据管道的字段完整性和结构一致性。
它不适合也绝不能用于:作为投资决策的唯一依据;替代对数据完整性、时效性和延迟特性的独立验证;高频交易或对延迟敏感的自动化执行;未经过人工复核直接用于生产系统或资金操作。
这些边界不是免责条款,是使用金融数据的基本常识。
五、这篇文章不能证明什么
本文没有对任何一款AI工具做横向测评或排名。Kimi、豆包、DeepSeek、问财、Wind都只是类型代表,实际表现在不同版本下可能存在差异。
本文不能证明“接入真实行情数据后AI分析更准确”“使用某一数据源能提高投资表现”“AI结合行情数据可以跑赢市场”。这些推断不在讨论范围内。
下次和AI聊股票之前
先做一件事。打开你常用的那个AI工具,问它一个具体的行情问题,然后追问三句:
“这个数据从哪来?”
“对应哪个时间?”
“我能不能复核?”
看它是逐一给出具体、可验证的答案,还是在流畅的措辞中把问题绕开。回答的语气从来不是判断标准。能经得起追问的,才值得放进你的决策链条。
全球范围的研究已经反复印证同一个判断:AI金融工具的能力在快速进化,但数据验证、监管规范和用户认知还远远没跟上。在这个差距弥合之前,先追问数据来源、先核查时间戳、先确认字段含义——这些习惯,就是你最可靠的护身符。
如果你正在做AI Agent、金融研究脚本或行情应用,当你需要让AI在分析之前先拿到一份可查、可核、可复现的真实数据时,TickDB可以作为候选的数据入口之一。先让AI查到数据,再让它分析。这个顺序本身,就是一种判断力。
参考文献
- 国家金融监督管理总局,《关于银行业保险业人工智能安全开发应用的指导意见》(金发〔2026〕8号),2026年。
- Cambridge Centre for Alternative Finance, The Cambridge Fintech AI Report 2025: Global AI Adoption in Financial Services, University of Cambridge, 2025. 覆盖全球151个司法管辖区、628份调查响应的跨国行业调研。
- Siebert Financial, The Risks of AI in Personal Finance: Algorithmic Bias, Data Privacy, and Hallucination, Siebert Research, 2025. 从算法偏差、数据隐私黑盒和模型幻觉三个维度分析AI个人理财工具风险的研究报告。
- U.S. Securities and Exchange Commission, Investor Alert: Artificial Intelligence and Investment Fraud, Investor.gov, 2024.
- International Organization of Securities Commissions (IOSCO), The Use of Artificial Intelligence and Machine Learning by Market Intermediaries and Asset Managers, Final Report, 2021.
通过 TickDB API 获取实时行情数据
一个 API 接入外汇、加密货币、美股、港股、A股、贵金属和全球指数的实时行情。支持 WebSocket 低延迟推送,免费开始使用。
免费领取 API Key查看 API 文档