Python 量化交易数据存储:第一版先别写架构,先留下失败现场
作者: TickDB Research · 发布: 2026/6/23 · 阅读: 10
标签: F12, 掘金 / A061
摘要
很多人的第一版行情入库脚本看起来是成功的:定时请求、解析 JSON、写入数据库。直到一周后回测结果异常,才发现某些时段返回过空数组,某个 symbol 被写错过,timestamp 还混过秒和毫秒。真正的问题不是脚本没跑,而是失败没有留下现场。本文以 TickDB REST API 的 ticker 和 kline 端点作为示例,演示最小落库闭环的核心设计——主表存成功记录并保留原始快照,日志表存失败记录并留下完整上下文。读完你会拿到两张可直接执行的建表 SQL、一个 30 行的字段校验函数,以及一份覆盖八个失败分支的处理速查表。
{kind=link}
很多人的第一版行情入库脚本,看起来是成功的:定时请求、解析 JSON、写入数据库。直到一周后回测结果异常,才发现某些时间段返回过空数组,某个 symbol 被写错,timestamp 还混过秒和毫秒。真正的问题不是脚本没有跑,而是失败没有留下现场。
第一版数据管道最重要的不是让数据流过去,而是让每一条缺失、异常和被拒绝入库的数据,都能被解释。
行情数据自动落库的最小闭环,不是“定时任务 + 数据库”这么简单。你需要先想清楚三件事:每次请求后必须核对哪些字段、核对失败时怎样不丢失现场、以及未来换端点或改频率时怎样不推翻重来。 本文给出的方案,就是用两张结构固定的表、一个按端点分别核对的校验函数,让第一版落库脚本在半天内跑起来。
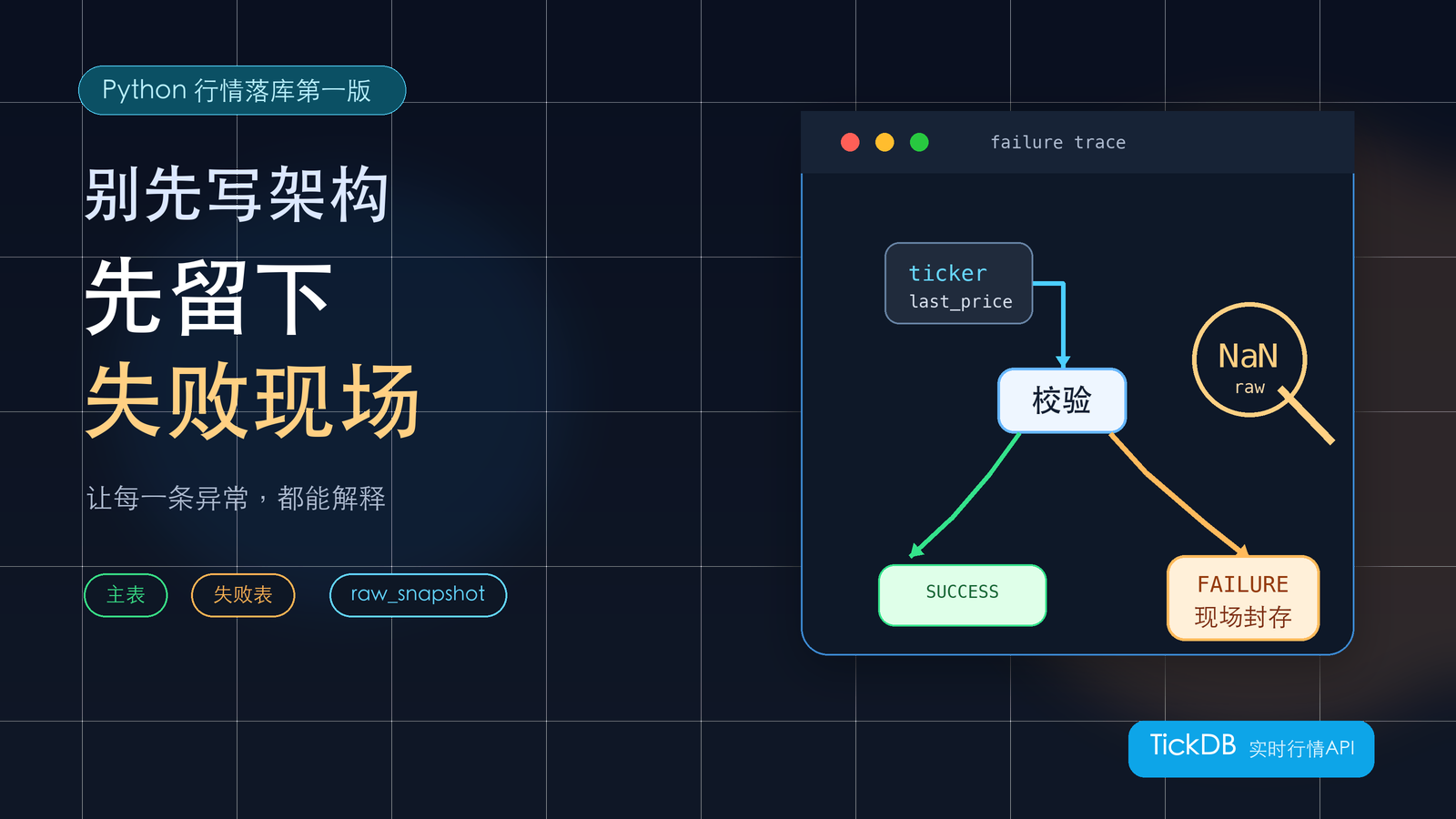
1. 最小落库流程:五步闭环
整个脚本的骨架非常直白,五个步骤循环执行:
定时触发 → 请求端点(ticker / kline)
→ 核对关键字段
→ 通过:写入主表,保留原始响应快照
→ 失败:写入日志表,记录失败原因和原始响应
- 定时触发:使用系统 crontab 或 Python
schedule库,按分钟或小时触发。第一版建议从低频开始(如每 5 分钟一次),跑稳后再调高频率。 - 请求端点:ticker 和 kline 是两条独立的路径,必须分开请求、分开核对。不要写一个通用函数同时处理两种返回结构。
- 字段核对:检查
code、data非空、symbol一致、数值字段可解析、timestamp语义明确。这一步是整个落库流程的核心——核对不通过的数据,不应进入主表。 - 写入主表:只保存核对通过的记录,同时保留服务端原始 JSON 快照,方便后续排查。
- 失败写日志表:保存完整的错误上下文,包括请求参数、失败原因、原始响应体,方便回溯和统计失败模式。
{kind=link}
2. 本文示例数据源说明
本文用 TickDB 的 ticker 和 kline 作为示例,是因为这两个端点刚好覆盖了“快照行情”和“K 线数组”两类常见结构。重点不在于绑定某个数据源,而是演示一个通用原则:端点结构一变,字段路径、timestamp 语义和失败分支都必须重新确认。
TickDB 的 ticker 端点返回 data 数组,数值字段以字符串给出;kline 端点返回 data.klines[] 数组,每条 bar 有独立的 OHLC 和时间字段。鉴权方式统一(X-API-Key Header),你在写核对逻辑时能复用同一套异常处理骨架。但 ticker 的价格字段是 last_price,kline 的 OHLC 在 data.klines[] 里——两个端点的字段路径必须分别核对,不能交叉取值。
你用这两个端点跑通落库逻辑后,再换其他数据源时,只需要改字段路径和 timestamp 语义,核对骨架不用变。
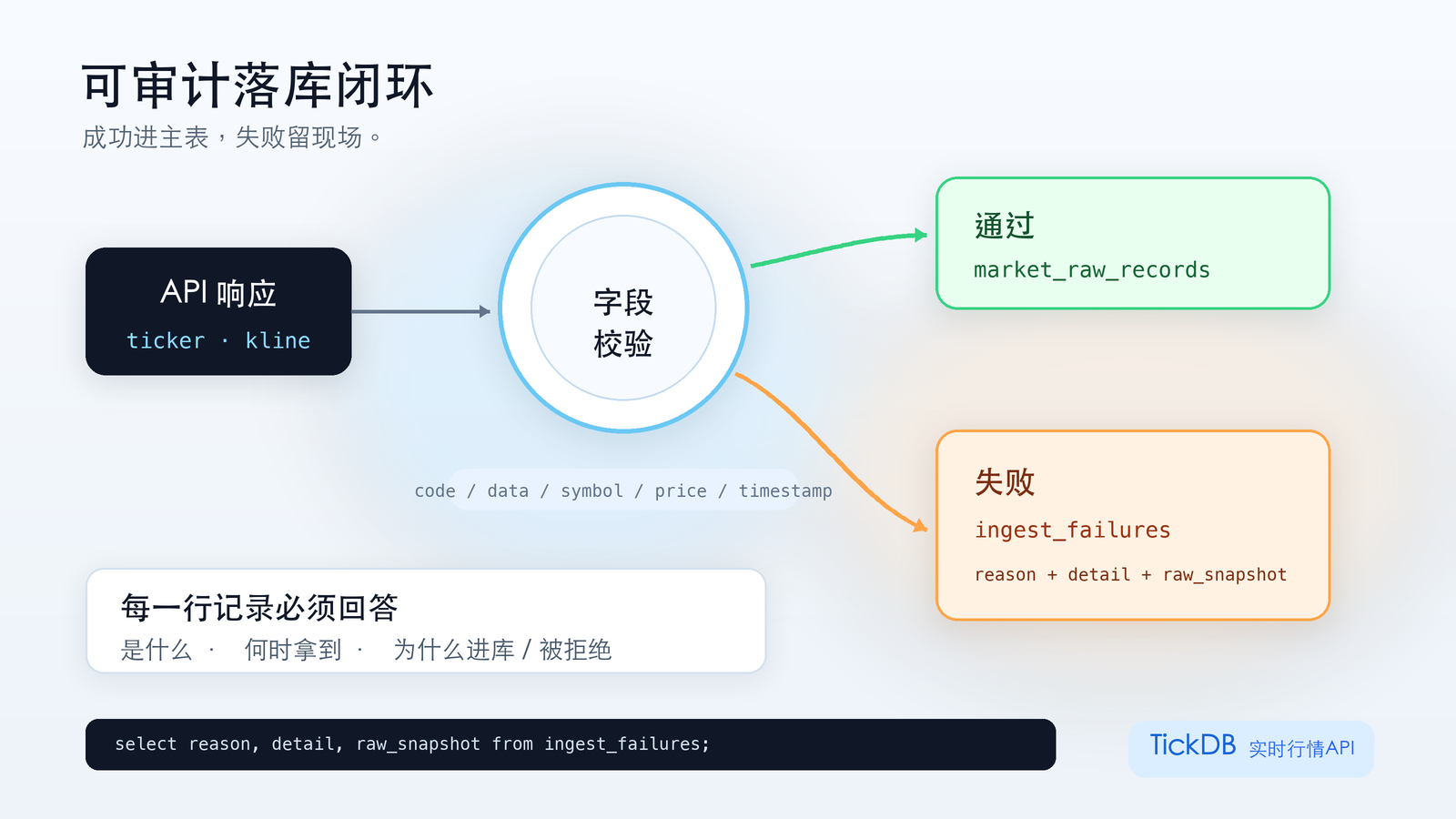
3. 最小落库表:两张表的 DDL
落库表的核心原则是:每一行数据都能被独立审计,不需要回头翻日志才能确认这条记录当时是怎么进来的。
主表:存储核对通过的成功记录
CREATE TABLE market_raw_records (
id INTEGER PRIMARY KEY AUTOINCREMENT,
symbol TEXT NOT NULL,
endpoint TEXT NOT NULL, -- 如 'ticker'、'kline_1d'
payload_timestamp INTEGER, -- 行情源时间戳,原样存储,不转换单位
checked_at TEXT NOT NULL, -- 客户端核对通过时间,ISO 8601 格式
status TEXT NOT NULL DEFAULT 'success',
note TEXT, -- 异常说明或'核对通过'
raw_snapshot TEXT NOT NULL, -- 原始响应 JSON 字符串
created_at TEXT DEFAULT CURRENT_TIMESTAMP
);
日志表:存储核对失败的完整现场
CREATE TABLE ingest_failures (
id INTEGER PRIMARY KEY AUTOINCREMENT,
symbol TEXT NOT NULL,
endpoint TEXT NOT NULL,
checked_at TEXT NOT NULL, -- 失败发生时间
reason TEXT NOT NULL, -- 失败原因,如 'empty_data'、'field_error'
detail TEXT, -- 详细错误描述
raw_snapshot TEXT, -- 原始响应体(如果能拿到)
created_at TEXT DEFAULT CURRENT_TIMESTAMP
);
两个时间戳的区分,是整个落库设计中最容易被忽视的细节。
payload_timestamp是行情源告诉你的时间。ticker 通常取自timestamp字段,kline 每根 bar 有自己的时间字段(如time)。它代表“行情发生在什么时候”。checked_at是你的脚本把这条数据写入本地数据库的时间。它代表“你什么时候拿到了这条数据”。
当 checked_at 与 payload_timestamp 差距异常时,就是你发现网络延迟或数据积压的第一条线索。如果落库表只存一个时间,这个线索就永远丢了。
对于 kline,每根 bar 有独立的时间字段。第一版建议逐 bar 拆开存储,每条记录对应一根 K 线,这样后续分析不需要再解 klines 数组。
4. 字段校验函数:30 行最小实现
下面是一个可直接复用的 ticker 校验函数,覆盖 code、data、symbol、last_price、timestamp 五个核心检查点。kline 的校验逻辑类似,但字段路径要切换到 data.klines[] 中的 OHLC 和时间字段。
from decimal import Decimal, InvalidOperation
def validate_ticker(response: dict, expected_symbol: str) -> dict:
"""
校验 ticker 返回结果。通过返回 {'ok': True, 'data': item},
失败返回 {'ok': False, 'reason': str, 'raw': response}。
"""
# 检查业务码
if response.get("code") != 0:
return {"ok": False, "reason": f"code={response.get('code')}", "raw": response}
# 检查 data 数组
data = response.get("data", [])
if not isinstance(data, list) or len(data) == 0:
return {"ok": False, "reason": "data is empty", "raw": response}
item = data[0]
# 检查 symbol
if item.get("symbol") != expected_symbol:
return {"ok": False, "reason": f"symbol mismatch: expected {expected_symbol}, got {item.get('symbol')}", "raw": response}
# 检查 last_price
raw_price = item.get("last_price")
if not isinstance(raw_price, str) or not raw_price.strip():
return {"ok": False, "reason": "last_price missing or empty", "raw": response}
try:
price = Decimal(raw_price)
if not price.is_finite():
return {"ok": False, "reason": f"last_price not finite: {raw_price}", "raw": response}
except (InvalidOperation, ValueError):
return {"ok": False, "reason": f"last_price unparseable: {raw_price}", "raw": response}
# 检查 timestamp(必须为整数且非 bool)
ts = item.get("timestamp")
if ts is None or isinstance(ts, bool) or not isinstance(ts, int):
return {"ok": False, "reason": f"timestamp invalid: {ts}", "raw": response}
return {"ok": True, "data": item}
这个函数的核心设计是:任何失败都返回完整的 raw 响应体。调用方拿到失败结果后,直接把 reason 写入日志表的 detail 字段,把 raw 写入 raw_snapshot 字段——失败现场就完整保留下来了。
5. 失败分支一览
落库脚本的健壮性,取决于失败分支是否覆盖了从网络层到语义层的完整链路。
| 失败场景 | 处理方向 |
|---|---|
| 请求超时 | 写入日志表,记录 timeout 和请求参数;可设置有限重试(如最多 3 次),避免无限等待 |
| HTTP 状态码非 2xx | 检查 Key 有效性和端点可用性;写入日志表并保留响应体 |
| JSON 解析失败 | 保留原始响应文本,检查数据源是否返回 HTML 错误页而非 JSON |
| 业务码非 0 | 根据错误码决定是否重试;鉴权类错误(如 Key 无效)禁止重试,避免被封 |
data 为空 | 检查 symbol 格式、权限和当前时段;写入日志表,不自行补默认值 |
| 返回 symbol 与请求不一致 | 硬阻断,可能为数据源 bug 或参数写错 |
Decimal 解析失败或 NaN/Infinity | 硬阻断,记录原始字符串,不默认成 0 |
| timestamp 单位无法确定 | 保留原始值并标记“待确认”,不参与后续时间计算 |
每一条失败记录都应该带上 raw_snapshot。 一个月后你回看日志表,如果没有原始响应体,你无法判断当时的失败是数据源返回了异常结构,还是你的脚本逻辑有 bug。
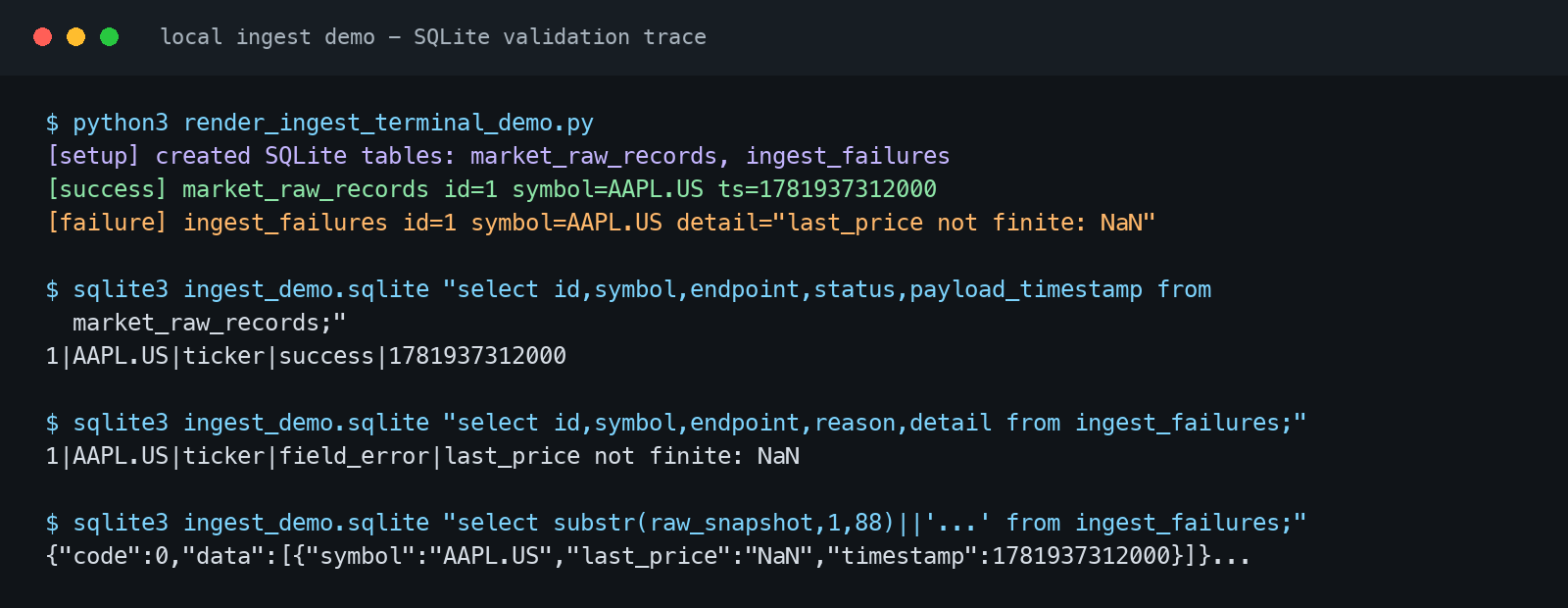
示例失败记录:
symbol: AAPL.US
endpoint: ticker
checked_at: 2026-06-20 14:35:12
reason: field_error
detail: last_price 解析失败,原始值为 "NaN"
raw_snapshot: {"symbol":"AAPL.US","last_price":"NaN","timestamp":1718894112000}
这条记录告诉你:2026 年 6 月 20 日下午两点半,AAPL.US 的 ticker 请求拿到了一个 "NaN" 价格。你不需要再翻代码或抓包,直接在日志表里就能定位到这条异常——raw_snapshot 里还有完整的返回体,方便判断是数据源问题还是网络问题。
{kind=link}
6. 边界:这不是生产级流水线
本文的落库脚本第一版只解决“定时拉取并可靠记录”的问题。它没有包含:
- 连接池、并发请求或严格的重试队列;
- 数据库主从、备份和监控告警;
- WebSocket 持续推送场景的落库(那是另一套架构,需要处理断线重连和心跳);
- 对延迟、SLA 或数据完整性的任何承诺。
它适合个人研究脚本、小批量 symbol(十几个以内)的分钟级快照存储。当你需要处理上百个 symbol 或秒级更新时,需要在当前骨架基础上补上队列、连接管理和异常恢复机制。
7. 下一步
- 把上面的两张 DDL 在你的 SQLite 里执行,建好
market_raw_records和ingest_failures表。 - 把
validate_ticker函数复制到你的脚本里,用 TickDB 的 ticker 端点跑一次AAPL.US,手动验证成功和失败两条路径。 - 加上
schedule或 cron 定时执行,稳定运行一个交易日后,检查日志表里出现的失败类型——它们会告诉你下一步该优化哪段核对逻辑。
📡 本文以 TickDB REST API 作为行情数据示例。接口文档见 docs.tickdb.ai。本文仅讨论数据落库的工程方法,不构成投资建议。
通过 TickDB API 获取实时行情数据
一个 API 接入外汇、加密货币、美股、港股、A股、贵金属和全球指数的实时行情。支持 WebSocket 低延迟推送,免费开始使用。
免费领取 API Key查看 API 文档