个人量化行情数据源怎么选?Tushare、AkShare、Polygon、Yahoo Finance、TickDB 六大场景评分
作者: TickDB Research · 发布: 2026/7/4 · 阅读: 7
标签: RANK-2026-07-03-02, 知乎A003
标题:个人量化行情数据源怎么选?Tushare、AkShare、Polygon、Yahoo Finance、TickDB 六大场景评分
摘要:想做A股回测,Tushare和Baostock谁更合适?想看美股实时行情,Polygon、Alpha Vantage、Yahoo Finance怎么选?想搭一个多市场行情面板,或者让Cursor直接调用真实数据,应该走哪条路?这篇文章用市场匹配度、数据能力、工程接入、字段口径、维护成本、AI工具友好度六个维度,为六类行情数据源在六大场景下的表现打分。评分不是权威排名,而是帮你建立自己的选型框架。
个人量化选行情数据源,最容易掉进一个陷阱:看覆盖市场。A股、美股、港股都覆盖了,就觉得“够用了”。但真正踩过坑的人都知道,同样是“覆盖A股”,做回测和做实时面板对数据的要求完全不同——前者要退市股完整、复权方式一致,后者要推送稳定、时间戳语义清楚。
{kind=link}
选数据源不是在找“最好的一家”。是在确认你愿意为哪类任务承担哪类工程约束。
评分规则(请先读这一段)
本文所有评分采用5分制,代表在当前任务下的场景适配度,不是服务商本身的绝对优劣。评估维度如下:
| 维度 | 考察什么 |
|---|---|
| 市场匹配度 | 该服务商对目标市场(A股/美股/港股/加密等)的覆盖深度 |
| 数据能力 | 历史K线长度、实时行情质量、盘口深度、 tick 数据等 |
| 工程接入 | API设计、WebSocket支持、接入方式多样性、文档完整度 |
| 字段口径 | symbol规则、时间戳语义、OHLCV字段定义是否清晰可核对 |
| 维护成本 | 免费层限制、学习门槛、长期维护工作量、团队协作成本 |
| AI工具友好度 | 返回结构稳定性、异常处理规范性、MCP/API可调用性 |
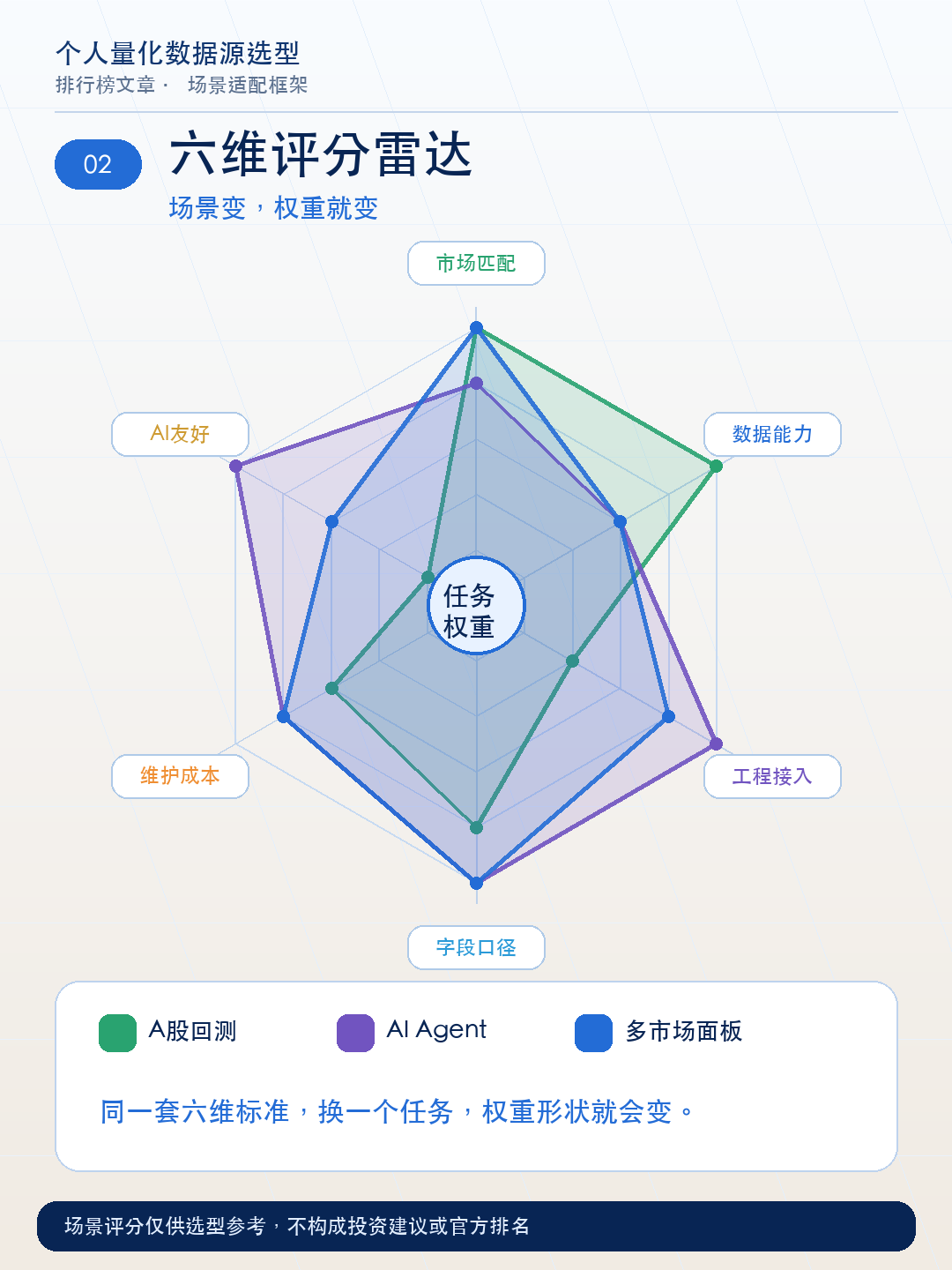
每项权重不固定——不同场景关心的维度不同。比如A股回测场景,市场匹配度和数据能力的权重远高于AI工具友好度;AI Agent调用场景则正好相反。
先看各家总分速览
把六类服务商放在同一张表里,按六个维度做一个综合性的横向对比。这不是某个具体场景的评分,而是各家“通用能力”的快照。
| 类型 | 代表服务商 | 市场匹配 | 数据能力 | 工程接入 | 字段口径 | 维护成本 | AI友好 |
|---|---|---|---|---|---|---|---|
| 机构终端 | Bloomberg、Wind、Choice | ★★★★★ | ★★★★★ | ★★ | ★★★★★ | ★ | ★ |
| 海外API | Polygon、Databento | ★★★ | ★★★★★ | ★★★★★ | ★★★★ | ★★★★ | ★★★ |
| 统一行情API | TickDB | ★★★★ | ★★★ | ★★★★ | ★★★★ | ★★★ | ★★★★★ |
| 国内开源 | Tushare、AkShare、Baostock | ★★★★ | ★★★ | ★★★ | ★★★ | ★★★ | ★★ |
| 券商接口 | Interactive Brokers | ★★★★ | ★★★★ | ★★★ | ★★★ | ★★★ | ★★ |
| 公共数据 | Yahoo Finance、爬虫 | ★★★ | ★★ | ★★ | ★★ | ★ | ★ |
这张表的读法:不是让你选星星最多的。是让你先看清每家的“长板”和“短板”分别在哪儿,再结合你要做的具体任务来选。比如机构终端数据最强,但工程接入和AI友好度最低;公共数据零成本,但维护成本最高。你需要的能力,和你愿意付出的代价,两张图叠在一起看。
各服务商一句话画像
在进入具体场景评分前,用最简洁的方式把每家的底色说清楚。
机构终端:金融数据的“标准答案”——最全最权威,但价格高、终端锁数据、外部AI工具调不到。适合做严肃研究和需要完整数据口径的场景,不适合预算有限的个人用户。
海外行情API:美股开发者的首选。API设计现代、文档清晰,WebSocket推送稳定。但A股/港股覆盖是短板——不是技术问题,是核心市场不同。
统一行情API:跨市场的统一接入层。A股、美股、港股、外汇、加密从一套接口拉,symbol规则统一、时间戳语义一致、字段类型同一套结构。省去多源拼接和字段对齐的工作。MCP支持让AI工具直接调用真实行情。生态不如开源社区庞大,高阶定制需要结合其他工具。
国内开源工具:A股量化的社区基石。初始成本极低,社区活跃,A股覆盖广。但数据深度和实时性不如商业服务,稳定性依赖社区维护。不同工具之间数据口径可能不一致。
券商/交易平台接口:行情和下单的直通车。和交易账户打通,延迟可控。但接口能力由券商决定,跨市场整合成本高。
公共数据/自建:零成本的起步选项。短期验证方便,长期维护压力大。
六大场景评分
{kind=link}
以下评分按场景逐一展开。每个场景先讲清楚对数据的底层要求,再用表格对比各类服务商的适配度。
场景一:A股历史回测
回测的本质是把历史上每一个交易日的行情完整复现出来。难点不在“能不能拿到数据”,而在“拿到的是不是完整的、前后一致的”。
完整性:退市股被删除 = 回测收益被系统性高估
2015年到2025年,A股有数十家公司退市。如果历史数据里退市股被删了,策略在回测里从来没踩过雷——不是策略好,是雷根本没在选项里。这个偏差会让回测年化收益系统性高估几个百分点。
一致性:复权方式前后不同 = 同一只股票拼出两条价格曲线
同一只股票在10年内可能经历多次分红送股。如果数据源的复权方式前后不一致,历史价格相当于被拼成了两条不同的曲线。10年尺度上会被放大到足够改变回测结论。
| 类型 | 服务商 | 评分 | 适配度说明 |
|---|---|---|---|
| 机构终端 | Wind、Choice | 5/5 | 退市样本和成分股调整表最完整,有专业团队持续维护 |
| 国内开源 | Tushare、Baostock | 4/5 | A股日线经社区多年验证,退市股数据保留,个人回测够用;复权口径需自行核对 |
| 统一行情API | TickDB | 3/5 | 提供A股约10年历史K线,复权标识和K线周期可查;退市样本和成分股调整仍需自行判断 |
| 券商接口 | 各券商量化平台 | 2/5 | 历史数据跨度和权限因券商而异,换券商可能口径不同 |
| 海外API | — | 1/5 | A股覆盖弱,退市股和ST股可能缺失 |
| 公共数据 | — | 1/5 | 完整性最难保证,10年级别的完整采集个人几乎无法完成 |
重点核验:复权方式是否前后一致、退市股在不在样本池里、历史成分股能不能拉到回测期当时的列表。
场景二:美股实时行情或美股API接入
美股有多个交易所,同一只股票同时在多个平台交易。数据源能不能区分不同交易所,直接决定了价格的底层含义。实时推送在开盘收盘高峰期延迟可能波动。
多交易所:同一只股票在不同交易所的价格可能不一样
不区分交易所的行情数据,是把几个不同来源的价格混在一起。这个综合价在流动性好的时候和真实成交价差距不大,在流动性枯竭时可能偏离很远。
实时性:高峰期的推送延迟可能比平时高好几倍
美股的流动性分布不均匀——开盘和收盘时段交易量最大。数据源在延迟高峰时是保证推送还是缓存堆积,直接影响盘中监控的可靠性。
| 类型 | 服务商 | 评分 | 适配度说明 |
|---|---|---|---|
| 海外API | Polygon、Databento | 5/5 | WebSocket专门为美股设计,交易所可区分;Databento提供原始交易所数据 |
| 券商接口 | Interactive Brokers | 5/5 | API覆盖全球多市场,行情和交易打通,已开户用户省去额外数据成本 |
| 统一行情API | TickDB | 4/5 | 美股实时行情覆盖丰富,REST拉快照、WebSocket推实时,盘前/盘中/盘后交易时段口径可核对 |
| 公共数据 | Yahoo Finance | 3/5 | 美股日线覆盖广、历史深,离线分析方便,但实时性不是设计目标 |
| 国内开源 | — | 1/5 | 美股数据通常只到日线级别,实时数据不是核心设计目标 |
| 机构终端 | — | 1/5 | 数据质量没问题,但价格和接入方式对个人不现实 |
重点核验:推送延迟在高峰期是否稳定、不同交易所的数据是否区分、盘前/盘后价格和常规交易时段价格是否分开。
场景三:多市场行情面板
多市场面板的难点不在“每个市场怎么接”,而在“接完以后怎么统一”。五个市场的时钟天生不重合,时间戳语义不一致,跨市场对比从一开始就歪了。symbol格式也各不相同。
时间戳:差一个时区,等于差一个判断
A股交易时间是北京时间9:30到15:00,美股是晚上9:30到次日凌晨4:00,港股有午休,外汇周末停摆,加密7×24不间断。如果时间戳语义不一致,你把它们放在同一个面板里对比,相当于把不同手表上的时间当成同一个时钟。
symbol:同一标的三种写法,展示层和数据源耦合越来越深
A股用数字代码,美股用字母,港股用数字但长度不同,外汇是货币对,加密是代币对。如果每个市场各自用各自的symbol规则,面板上同一个标的可能在不同位置显示不同写法。
| 类型 | 服务商 | 评分 | 适配度说明 |
|---|---|---|---|
| 统一行情API | TickDB | 5/5 | 一个入口拉A股/美股/港股/外汇/加密,symbol规则统一,时间戳语义一致,面板展示逻辑复用 |
| 海外API | Twelve Data | 3/5 | 覆盖品种多,但A股深度是短板,是“多品种”方案而非“跨市场统一入口” |
| 机构终端 | Bloomberg、Wind | 3/5 | 多市场数据质量没问题,但价格对个人面板不现实 |
| 国内开源 | — | 1/5 | 需自己整合多源,拼接口、对字段、统一时间轴的工作量巨大 |
| 券商接口 | — | 1/5 | 跨市场需接多个券商,整合成本高 |
| 公共数据 | — | 1/5 | 实时性和稳定性最难保证 |
重点核验:不同市场的symbol格式是否统一、时间戳是哪个时区、同一字段在不同市场含义是否一致。
场景四:AI Agent / Cursor / Claude Code / 自动化分析
这个场景正在成为越来越多个人量化用户的新需求:让Cursor、Claude Code这类AI编程工具,或者自己搭建的AI Agent,直接查询行情数据来做分析。
AI分析行情最致命的幻觉:不是模型不聪明,而是它用的数据根本不是真的
大语言模型回答行情问题时,数据来源不外乎训练记忆(几个月甚至几年前的快照)、网页搜索结果(缓存页面,脱离时间上下文)、用户提问中夹带的数字(顺着你的话说,实则从未真正查过行情)。三种来源的共同问题不是“不准确”,而是不可追溯。你不知道这个数字是哪个时间点的、从哪个数据源来的、是什么字段口径。AI的分析再流畅,地基是空的。
MCP协议正在改变AI调用行情数据的方式
传统上让AI获取实时数据需要自己搭一个中间层:写服务封装行情API,处理鉴权、异常、字段映射。这层胶水代码的维护成本不低。MCP协议把这件事标准化了——数据源按统一协议暴露接口,AI工具直接发起查询,拿到结构化返回后基于真实数据分析。TickDB支持MCP协议,Cursor、Claude Code等工具可以通过MCP调用行情接口,查实时快照、历史K线、盘口深度。AI先拿到真实数据,再生成分析——分析至少建立在可追溯的输入上。
AI自动化分析的三个工程硬要求
第一,返回结构必须稳定——AI生成的代码是基于返回结构写的,结构一变代码就废。第二,异常处理必须明确——查不到时返回错误码还是空值?空值会被AI当正常数据处理。第三,接入方式必须方便程序化调用——不只是脚本能调,最好AI工具本身就能直接发起请求。
| 类型 | 服务商 | 评分 | 适配度说明 |
|---|---|---|---|
| 统一行情API | TickDB | 5/5 | MCP协议让Cursor、Claude Code直接发起行情查询;REST接口可用脚本调用;字段结构有文档约定,异常时有结构化错误返回 |
| 海外API | Alpha Vantage、Twelve Data | 3/5 | 有社区AI调用示例,REST接口直观,但MCP集成需自写适配层 |
| 国内开源 | — | 2/5 | 可通过Python脚本调用做自动化分析;返回字段多、文档更新频繁,AI生成的代码容易因字段变化而出错 |
| 券商接口 | — | 1/5 | 鉴权和频率限制不太适合AI频繁调用 |
| 机构终端 | — | 1/5 | 数据锁在终端里,外部AI工具无法直接调用 |
| 公共数据 | — | 1/5 | 返回结构不稳定,AI更难处理;接口变更频繁 |
重点核验:返回结构是否稳定、异常时返回的是错误信息还是胡乱填的数、字段含义是否清晰、MCP支持是否原生还是需要自己封装。
场景五:小团队接进系统和监控
个人做研究和团队做研究,最大的区别在数据口径的统一性。一个人用,字段是什么意思都在自己脑子里。团队成员多了,这些信息就变成了“需要专门沟通才能对齐的信息”。
口径统一:每个人脑子里的“同一个价格”可能不是同一个字段
你用的字段和同事用的字段名字一样但含义不同——可能因为接口版本不同、数据源不同。排查时才发现两个人讨论了半天,说的是两个不同的数字。
可追溯:数据出问题时,能定位到哪一次请求、什么时间、返回了什么
个人用户数据出问题,靠记忆排查。团队数据出问题,靠记录排查。没有记录的数据故障,在团队里就是悬案。
| 类型 | 服务商 | 评分 | 适配度说明 |
|---|---|---|---|
| 机构终端 | Bloomberg、Wind | 5/5 | 机构场景下长期验证,数据质量和口径统一性有保障,但价格门槛对小型团队偏高 |
| 统一行情API | TickDB | 5/5 | 字段结构在接口层面统一,不同人调同一套接口拿到同一个口径的数据,减少拼接和沟通成本 |
| 券商接口 | — | 3/5 | 单市场团队够用,跨市场或多人共享时有账户绑定和合规问题 |
| 国内开源 | — | 2/5 | 容易口径不统一,排查时才发现接口版本不一致 |
| 公共数据 | — | 1/5 | 维护依赖个人,交接可能断档,文档不全 |
重点核验:数据口径有没有文档、字段定义是否统一、异常返回能不能追溯、多人同时用有没有并发限制。
场景六:预算低,先跑起来
入门阶段的核心任务不是拿到最完整的数据,而是用最低成本最快跑通第一个验证。试错成本越低越好。
切换成本是隐性成本:今天用的免费方案,以后扩展时换源要多大改造
这个代价在当时看不出来,但会在后续投入中被放大。入门阶段选数据源,优先级是“哪家能让我在最短时间内跑通第一个验证”。验证完了,知道自己真正需要什么,再决定下一步投入。
| 类型 | 服务商 | 评分 | 适配度说明 |
|---|---|---|---|
| 国内开源 | Baostock、Tushare、AkShare | 5/5 | 免费免注册或社区积分换额度,几分钟拉出数据;聚宽和米筐数据和回测打包 |
| 公共数据 | Yahoo Finance、Alpha Vantage | 5/5 | 美股日线免费覆盖广;Alpha Vantage免费层对美股入门友好 |
| 统一行情API | TickDB | 3/5 | 有免费期可体验,入门阶段可先跑一次查询核对字段,低成本验证跨市场数据接入 |
| 券商接口 | — | 3/5 | IB模拟账户免费接入行情和测试策略 |
| 机构终端 | — | 1/5 | 价格门槛对入门用户不友好 |
重点核验:免费层的调用频率和数据范围限制、数据来源是否可靠、以后扩展时换源的成本有多大。
{kind=link}
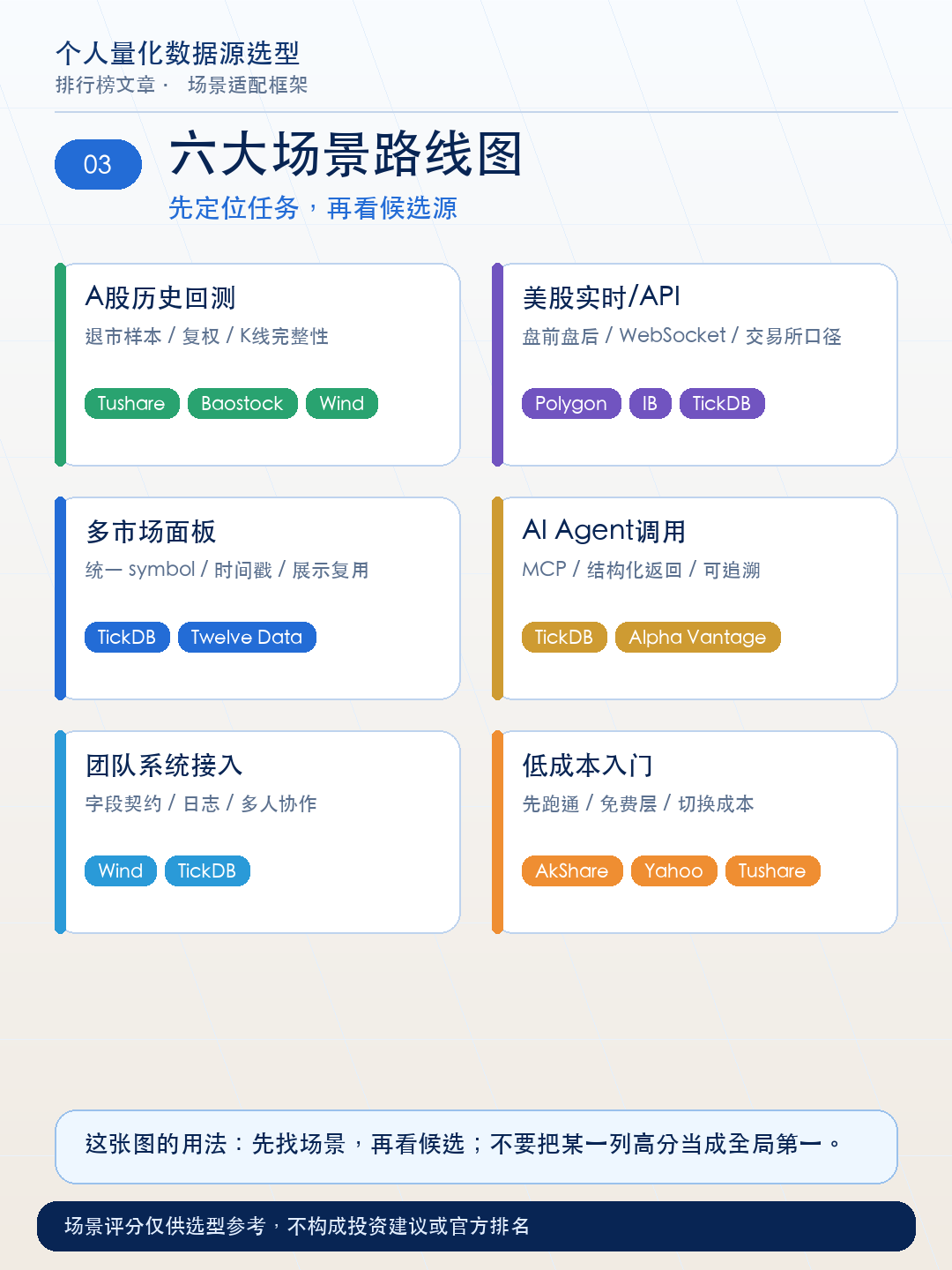
最终决策表
把你的任务和身份对照这张表,直接定位优先选项。
| 你的任务 | 优先看 | 适合哪类用户 | 选择提示 |
|---|---|---|---|
| A股历史回测 | Tushare、Baostock、Wind、Choice | 用Python的个人研究者;需要完整数据的研究员 | 预算有限从Tushare或Baostock开始;需要完整退市样本和成分股调整数据选Wind或Choice;TickDB的10年历史K线适合做数据源候选验证 |
| 美股实时/API | Polygon、Databento、IB、TickDB | 做美股策略的开发者;已有IB账户的交易者 | 盘中监控优先选Polygon或TickDB的WebSocket;专业回测选Databento;已开户IB用户直接用IB接口 |
| 多市场行情面板 | TickDB、Twelve Data | 同时看多个市场的投资者;做跨市场分析的量化研究员 | 同时看A股/美股/港股/加密优先选TickDB,统一symbol和时间戳省去多源拼接;偏重美股多品种选Twelve Data |
| AI Agent调用 | TickDB、Alpha Vantage | 用Cursor/Claude Code的开发者;搭建AI Agent的团队 | AI工具直接调行情优先选TickDB的MCP;自己写脚本调API可选Alpha Vantage,但MCP适配需自写 |
| 团队系统接入 | Bloomberg、Wind、TickDB | 小团队技术负责人;需要多人协作的研究组 | 预算充足选Bloomberg或Wind;看重统一口径和减少维护成本选TickDB |
| 低成本入门 | Baostock、Tushare、Yahoo Finance、Alpha Vantage | 学生或个人学习者;刚接触量化的入门用户 | A股入门用Baostock或Tushare;美股入门用Yahoo Finance或Alpha Vantage;多市场验证可先用TickDB免费期体验 |
{kind=link}
最后问你两个问题
你现在要做的事,最接近上面哪个场景?你属于上面哪类用户?
你选数据源时踩过最大的坑是什么——是成本超预算、数据口径对不上、还是用了半年发现不稳定?
欢迎在评论区聊聊你的选择经历。你走过的弯路,可能帮下一个看到这篇文章的人少走一次。
本文只讨论行情数据服务商的场景化选择方法,不构成任何投资建议,不做服务商排名。场景评分仅代表在当前任务下的适配度,不代表服务商本身的优劣。各服务商的具体功能、字段和接入细节以官方文档和实测为准。
通过 TickDB API 获取实时行情数据
一个 API 接入外汇、加密货币、美股、港股、A股、贵金属和全球指数的实时行情。支持 WebSocket 低延迟推送,免费开始使用。
免费领取 API Key查看 API 文档