实时行情API选型:个人研究员的五类场景与八项隐形成本
作者: TickDB Research · 发布: 2026/6/16 · 阅读: 112
标签: M06, 雪球 / A039
摘要: 个人研究员和小团队选实时行情数据源,常见的做法是对比功能列表或找一份综合排名。但研究任务不同,对数据形态、调用频率和脚本维护成本的要求完全不同。本文不提供排名,只提供一套决策框架:先按研究任务分类,再计算总成本,最后用自己的代表品种验证覆盖和脚本复用。
做量化研究的人,迟早会遇到一个问题:要选一个实时行情数据源。
这个问题的标准答案通常是找几份对比评测,列一张功能表,然后挑一个"综合最好"的。但用了一段时间后发现,当初选的时候很看重的某些功能,自己的研究里几乎没调用过;而每天在用的几个接口,返回字段的稳定性、参数设计的一致性、出问题时恢复的难易程度,选型时根本没仔细看。
问题出在选型顺序上。行情数据源没有脱离研究任务的统一第一名。 一个做单市场因子回测的人,和一个做跨市场监控脚本的人,需要的"好"是完全不同的。
本文是为自己做研究、自己决定工具、又要长期维护脚本的个人研究员和小团队决策者写的。核心问题是:怎样在成本、覆盖和脚本复用之间做取舍?
一、先分类,再选型:五类研究场景需要什么
{kind=link}
把研究任务分成五类,每一类对数据源的要求不同。先判断自己的任务落在哪一类或哪几类的组合里,再往下看。
| 研究场景 | 典型任务 | 对数据源的核心要求 |
|---|---|---|
| 1. 偶发查询与快速验证 | 验证一个想法,拉几段历史K线看一眼,不形成定期运行的脚本 | 接入快、参数直观、不需要复杂配置即可获取历史数据 |
| 2. 可重复的单市场研究 | A股单市场研究样本,每天跑同一批脚本,覆盖沪深全市场 | 接口稳定、返回结构一致、历史/实时数据边界清楚,停牌、除权除息等情况可用代表样本独立验证 |
| 3. 跨市场或多资产研究 | 同时研究A股和港股的相关性,或股票和期货的联动 | 多市场同一套接口规范,时区和交易日历可对齐,字段语义一致 |
| 4. AI辅助研究与工具调用 | 在ChatGPT或Cursor中让AI直接调用行情数据,AI写研究代码时自动获取数据 | 有AI可用的接入方式,返回结构对AI解析友好,不必每次手工下载和导入 |
| 5. 团队共享、长期运行的研究流程 | 多人共用一套数据管道,研究脚本需要长期维护和交接 | 有文档、有版本变更记录、接入方式支持脚本化和自动化,不依赖GUI操作 |
判断标准不是"哪一类更高级",而是"你的任务需要哪一类"。多数个人研究员的需求落在第一、二、四类的组合里。
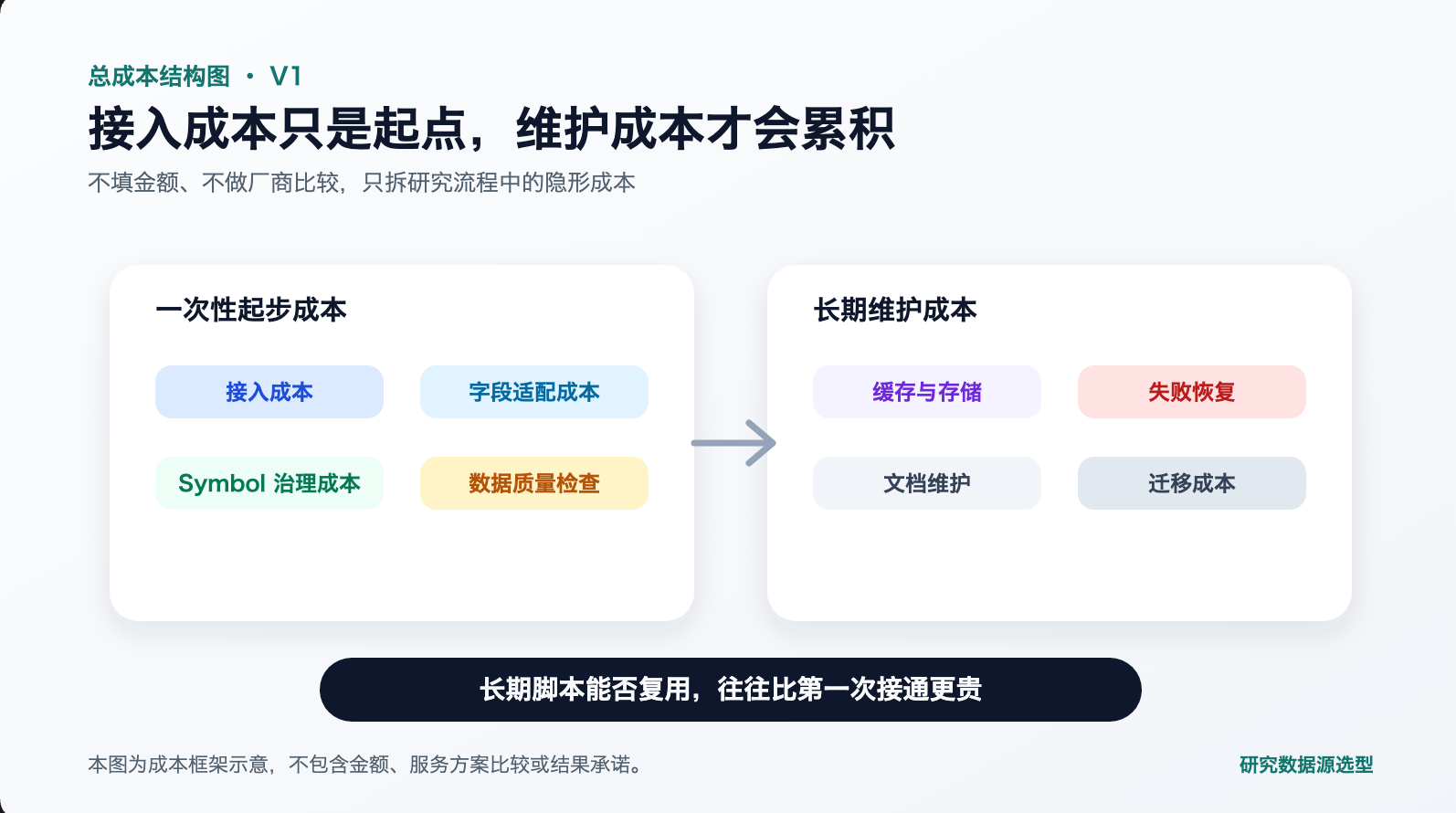
二、总成本不只是接入费:八项隐形成本
{kind=link}
选型时最容易只比较接入成本——接入门槛、权限流程是否清楚。但接入之后的时间成本,往往比接入本身高得多。
| 成本项目 | 具体内容 | 类型 |
|---|---|---|
| 接入成本 | 注册、获取权限、阅读文档、写第一段可用代码 | 一次性为主 |
| 字段适配成本 | 不同数据源返回字段命名不同,研究脚本需要逐一适配;换数据源时全部重写 | 每次换源重现 |
| Symbol治理成本 | A股的代码格式是否带后缀、港股的代码规则是否一致、美股是否区分交易所 | 持续 |
| 数据质量检查成本 | 停牌期间的价格处理、复权字段是否可用、异常值排查、时区对齐 | 每次任务启动 |
| 缓存与存储成本 | 原始响应要不要存、存多久、本地数据库还是文件、重复请求如何避免 | 持续 |
| 失败恢复成本 | 网络超时、限流、返回异常时,重试逻辑怎么写、中断的研究脚本怎么续跑 | 每次出问题 |
| 文档维护成本 | 数据源的字段含义、更新频率、已知限制,你自己记在哪里;半年后还看得懂吗 | 持续,多人更关键 |
| 迁移成本 | 当前数据源停止维护、使用条件变化、覆盖缩减时,迁移到新数据源需要改多少代码 | 低频但影响大 |
这八项里,接入成本通常最小。真正决定长期体验的是字段适配、数据质量检查和失败恢复三项——它们直接决定了你的研究脚本能在不盯着的情况下跑多久。
三、脚本复用:选型时最容易漏掉的维度
{kind=link}
研究脚本的生命周期往往比预期的长。今天写的一个因子计算脚本,半年后可能要换一个市场跑,或者换一个数据源验证。如果当初写脚本时,数据源的返回结构、参数命名、错误处理方式不一致,复用时就得逐行改。
用五个维度评估一个数据源对脚本复用的友好程度:
| 评估维度 | 好 | 差 |
|---|---|---|
| 参数稳定性 | 跨版本不变或兼容 | 更新后旧参数失效,静默改变默认值 |
| 返回契约 | 字段名和层级有文档且实际行为一致 | 字段名随数据源调整而变化,无文档或文档与实现不一致 |
| 错误处理 | 错误码清晰可编程判断,重试策略可统一封装 | 错误格式随接口变化,需要逐接口写判断逻辑 |
| 跨任务复用 | 多市场和品种共用同一套接口规范 | 不同市场需要不同的请求格式和解析逻辑 |
| 测试可重复 | 有明确的数据版本或时间戳记录 | 历史数据随数据源调整而变化,无法复现旧研究 |
这五个维度合在一起,回答的是同一个问题:一年之后,你的研究脚本还能不能跑。
四、覆盖验证:用自己的品种清单测
数据源的覆盖列表很长,但真正重要的只有你自己会研究或长期跟踪的品种。不要看数据源说"支持全市场",拿一张自己的代表品种清单去验证。
清单不用长,5到10个品种就够了,但需要覆盖你的研究场景里最关键的几类:正常交易的、历史有过停牌的、有过除权除息的、代码格式特殊的。
用这张清单验证四件事:
- 品种代码能不能正确识别;
- 历史日线数据是否连续,停牌期间是否明确标记;
- 分钟级数据的时间戳时区是否一致;
- 如果涉及多市场,同一套请求参数是否都能返回有效数据。
覆盖验证不是验证数据源"全不全",是验证"你的研究能不能跑通"。
五、Plan B:不是所有研究都需要统一抽象
读到这里,可能会形成一个印象:选数据源就是选一个最全面的统一入口。
不一定。不同任务对数据源的要求不在同一个量级上。
- 如果需求只是偶发查询,拉几段K线看看走势,一个文档清晰、接入简单的单市场数据源就够用了。过度建设统一抽象,反而增加了脚本维护的复杂度。
- 如果需求涉及持续行情推送、交易执行、复权或point-in-time历史版本等能力,这些每一项都需要独立核验。统一接口可以降低适配成本,但不能替代这些能力本身的验证。
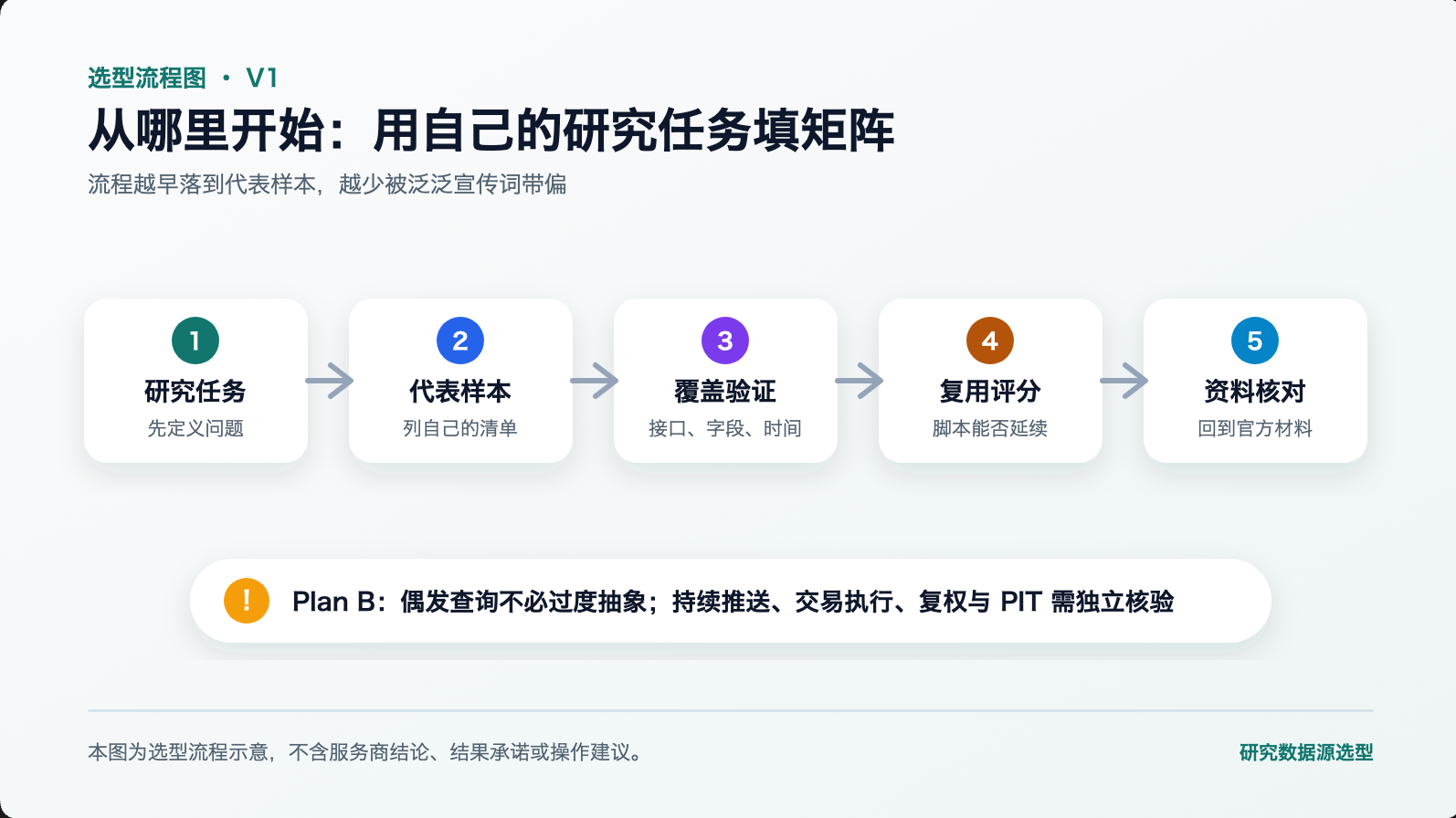
从哪里开始
{kind=link}
选型不需要一次做对所有决策。建议的顺序是:
- 写下自己最主要的一类研究任务,对应上面的五类场景表,确认需要的数据形态。
- 用自己的代表品种清单验证覆盖。
- 用脚本复用五个维度评估备选方案。
需要看具体的接入方式时,可以参考一个完整的验证流程来结构化地检验候选数据源。以 TickDB 为例,可以查看其官方文档与统一 GitHub 仓库,把它作为候选数据源之一,按自己的代表任务核对接入方式和脚本组织方式:
- 查官方资料核 symbol 规则:对比文档中的品种代码格式说明,检查你的代表品种清单能否被正确识别,多市场是否统一规则;
- 用小样本核返回结构:调用实时行情接口,查看 JSON 字段名、嵌套层级和数据类型,判断与你已有脚本的适配工作量;
- 对历史/实时边界按任务独立验证:获取日线或分钟线,检查停牌期间是否留空或填充,除权除息是否有明确字段;
- 用异常样本核错误处理:故意使用错误参数或断开网络,观察返回的错误码格式和重连后的数据恢复行为,评估失败恢复和跨任务复用成本;
- 如涉 AI 调用,只在支持相应入口的环境中验证解析友好度:让 AI 工具直接调用行情数据,检验返回结构是否便于 AI 准确提取和计算,不用再手工中转。
整个过程的核心不是找到完美答案,而是确保你的选择能经得起长期维护的检验。每项验证的结果都可以对应到前文的总成本表和脚本复用评分卡中,让选型从"凭感觉"变成"可复查"。
本文不能证明什么
本文仅提供研究用行情数据源的决策框架,不构成任何投资建议。本文不对任何具体数据源做推荐或排名,不讨论任何策略的有效性,也不能替代实际接入验证。每个研究者的需求和现有脚本体系不同,最终选择应基于自己的验证结果。
免责声明
文章内容为研究工具选型方法论讨论,不涉及具体投资标的,不构成投资建议。文中数据源描述基于公开文档和通用系统机制,非实测报告。市场有风险,投资需谨慎。
把你的研究任务对应到上面的五类场景里,你的代表品种清单上最先放哪几个品种?
通过 TickDB API 获取实时行情数据
一个 API 接入外汇、加密货币、美股、港股、A股、贵金属和全球指数的实时行情。支持 WebSocket 低延迟推送,免费开始使用。
免费领取 API Key查看 API 文档