策略写了3天,数据接了5天:全市场选股回测最容易被低估的工程债
作者: TickDB Research · 发布: 2026/5/12 · 阅读: 176
标签: B 类, 知乎, 回测
6986只A股做日频选股回测。策略代码写了3天,数据接入修了5天。
>
关键问题不是代码量,是复权因子方向用反了——前复权价格算信号,后复权净值算绩效,敞口漂了0.3%,半年累积偏离17%。回测年化22%,实盘只剩6%。
>
不是过拟合,是两把不同的尺子量了同一段行情。
{kind=link}
做全市场回测的人迟早要面对一个事实:数据中间件的维护成本,远高于策略开发本身。 你写的每个parser、每套字段映射、每个时区转换脚本,都是在给数据源的差异还债。
以下是这笔债的完整拆解。
回测的第一性原理:所有偏离都会在时间轴上被放大
一个日频回测跑半年,大概120个交易日。如果每天的系统性偏离只有0.3%,120天累积下来就是17%——刚好把年化22%吃成6%。这不是夸张,是复利公式的必然结果。
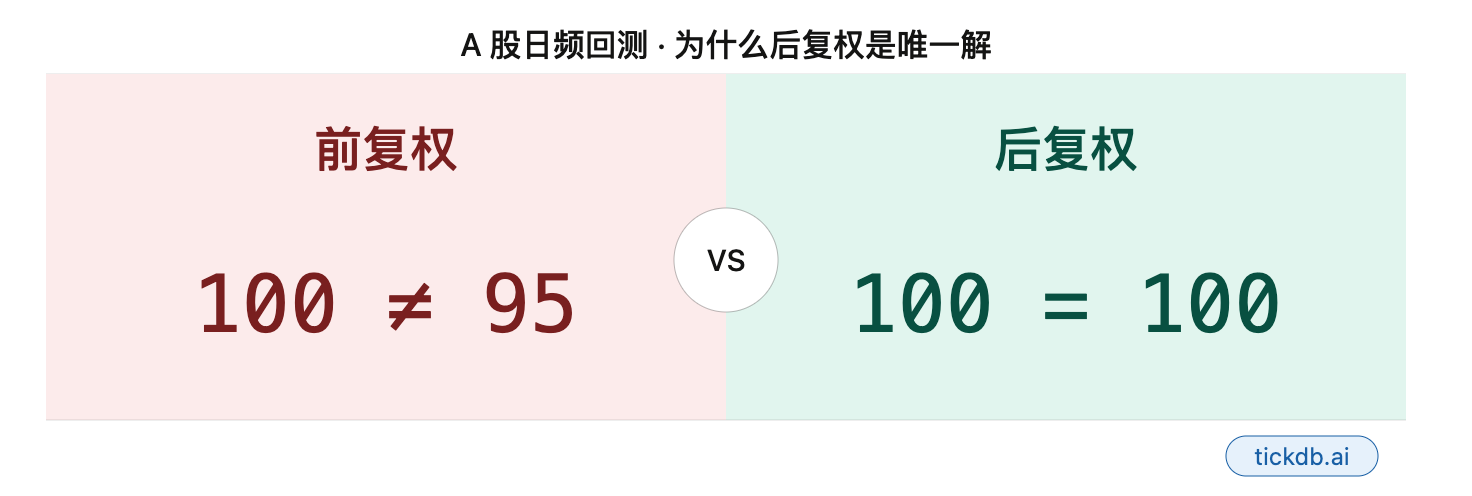
复权因子对齐:为什么T+1制度下后复权是唯一解
这是我踩过最深的坑。拆成五步说清楚。
{kind=link}
① 是什么
股票分红、送股、拆股后,价格会产生断崖式跳变。复权因子通过乘法链把这些断点衔接起来,让价格序列连续可比较。
| 复权类型 | 计算方向 | 价格基准 | 日频回测是否可用 |
|---|---|---|---|
| 前复权 | 向后修正历史价格 | 最新价 | ❌ 信号对应的历史价格会不断变动 |
| 后复权 | 向前累积除权因子 | 上市首日价 | ✅ 历史价格钉死,后续只追加因子 |
② 为什么后复权是唯一解
A股T+1制度下,你今天收盘后出信号,明天开盘才能交易。
前复权的致命问题:你11月10日生成的信号,基于当天收盘价。11月20日某只持仓股除权,数据源推送了新的前复权价格——你11月10日那个信号对应的历史价格就变了。回测引擎读到的,已经不是当时触发信号的那个价格。
后复权不存在这个问题。上市首日的价格是锚,后续所有除权事件只往上累积因子,历史价格纹丝不动。T+1下的信号-执行对应关系得以完整保留。
③ 怎么用
K线灌入回测引擎前,逐根bar做:
adj_close = close × 复权因子
⚠️ 复权因子的具体字段名,需要以 https://docs.tickdb.ai 中kline接口返回的实际键名为准。不同数据源的命名可能不同,接入前务必先print(bars[0].keys())确认。
⚠️ 别用last_price做计算——那是ticker快照字段,不带复权因子。kline用close,ticker用last_price,混用一次,全量结果偏移。
④ 有什么坑
我之前遇到的情况,整理成这张表:
| 坑 | 原因 | 后果 |
|---|---|---|
| 多数据源拼接基准不统一 | 一个用2010-01-01做基准日,另一个用上市首日 | 复权因子链在拼接点断裂,偏离逐步放大 |
| ticker和kline字段混淆 | ticker用high_24h/volume_24h,kline用high/volume | 日频K线整列偏差,且不会报错 |
| vnpy DataFeed中直接灌前复权close | 绩效计算默认复权净值逻辑 | 信号和绩效用的坐标系不同 |
⑤ 怎么优化
核心思路:单独拉取复权因子序列做本地缓存,向量化计算。用kline的close做基础价,配合缓存的因子列一次性做矩阵乘法。6986只品种的复权对齐,瞬间跑完。
打个比方——这跟ORM统一不同数据库SQL方言是一个道理:所有人面对同一个查询接口,方言的翻译和适配在底层一次性处理干净,上层不用关心底层接了几个数据源。
vnpy DataFeed对接:翻译层的脏活
vnpy回测引擎对DataFeed的输入有严格约定。你的数据源里少一个字段,或者品种代码后缀写错,回测不会报错——它只会静默地吐出错误的绩效数字。
| 步骤 | 操作 | 关键细节 |
|---|---|---|
| 第一步 | 继承BaseDataFeed,重写load_bar(days) | 按天吐出BarData列表 |
| 第二步 | 确保品种代码后缀正确 | 上海.SH(如600519.SH 贵州茅台),深圳.SZ(如300750.SZ 宁德时代) |
| 第三步 | BarData字段完整映射 | open_price/high_price/low_price/close_price/volume一个不能少 |
T+1常识级提醒:日频回测中,今日生成的信号只能在下一交易日执行。回测引擎里的信号日期和交易日期必须偏移一天。这个偏移不在代码里显式写,引擎内部处理,但你调参时必须意识到这个滞后。
到这里,原理层讲完了。但有一个问题值得先停一下:你上一次检查自己回测代码里的复权坐标,是什么时候?
如果你不确定答案,下面的代码实操部分会帮你一次性把这件事做对。
代码实操:从全量品种到回测报告,三道坎
下面三段代码可以直接跑,唯一依赖是requests、sqlite3、numpy和vnpy。
这套代码的价值不是教你写策略,而是帮你跳过手工拼接三个数据源的阶段,把数据接入的调试时间从5天压到30分钟。
Step 1:拉取6986只A股全量品种列表并缓存
这段代码我在本地跑了几个版本才稳定。最初的版本没做指数退避,批量请求触发了限流,拉取中断后本地缓存里缺了大概1400只股票,跑了两次回测都没发现——直到后来比对全量列表才知道少了一截。
import os
import time
import sqlite3
import requests
from typing import List, Dict
API_KEY = os.getenv("TICKDB_API_KEY") # 绝不硬编码密钥
BASE_URL = "https://api.tickdb.ai/v1"
HEADERS = {"X-API-Key": API_KEY}
def fetch_all_a_stock_symbols() -> List[Dict]:
"""通过 /v1/symbols/available 枚举全量 A 股品种,指数退避处理限流,SQLite 批量缓存。"""
conn = sqlite3.connect("tickdb_cache.db")
conn.execute(
"CREATE TABLE IF NOT EXISTS symbols (symbol TEXT PRIMARY KEY, name TEXT, exchange TEXT)"
)
# 先尝试读本地缓存
cached = conn.execute("SELECT COUNT(*) FROM symbols").fetchone()[0]
if cached >= 6000:
return [{"symbol": r[0], "name": r[1], "exchange": r[2]}
for r in conn.execute("SELECT symbol, name, exchange FROM symbols")]
# 正确端点:品种列表 /v1/symbols/available,不是 ticker 快照
url = f"{BASE_URL}/symbols/available"
backoff = 1
symbols = []
page = 0
while True:
try:
params = {"market": "CN", "type": "stock", "limit": 500, "offset": page * 500}
resp = requests.get(url, headers=HEADERS, params=params, timeout=10)
data = resp.json()
if data["code"] == 3001: # 限流,指数退避
time.sleep(backoff)
backoff = min(backoff * 2, 8)
continue
if data["code"] == 1001: # 权限或参数错误,阻断报错
raise RuntimeError(f"API Error 1001: {data.get('message')}")
if data["code"] != 0:
raise RuntimeError(f"Unexpected error {data['code']}: {data.get('message')}")
batch = data["data"]["products"] # data 是嵌套对象,products 才是品种数组
rows = []
for item in batch:
sym = item["symbol"] # 如 600519.SH, 300750.SZ
name = item.get("name", "")
ex = item.get("exchange", "")
symbols.append({"symbol": sym, "name": name, "exchange": ex})
rows.append((sym, name, ex))
# 批量写入,避免逐条触发 fdatasync()
conn.executemany("INSERT OR REPLACE INTO symbols VALUES (?, ?, ?)", rows)
conn.commit()
if len(batch) < 500:
break
page += 1
backoff = 1
except requests.exceptions.Timeout:
time.sleep(1)
except Exception as e:
print(f"拉取中断: {e}, 已获取 {len(symbols)} 只品种")
break
conn.close()
return symbols
核心是指数退避重试 + 批量缓存,不是请求速度。
code字段显式判断3001限流和1001阻断——3001退避等待,1001直接抛异常阻断,避免限流错误被静默吞掉。HTTP示例适用于快速集成,生产环境全量拉取建议走WebSocket长连接(端点:wss://api.tickdb.ai/v1/realtime),减少反复建连开销。
Step 2:日频K线批量拉取 + 复权对齐
字段名对照表先列清楚。这些差异是我之前踩坑时逐个比对的记录:
| 参数 | 正确写法 | 错误写法 | 说明 |
|---|---|---|---|
| 品种参数 | symbol= | symbols= | kline用单数形式 |
| 周期参数 | interval="1d" | period="1d" | 按API文档规范 |
| 时间字段 | time(毫秒UTC) | timestamp | ticker才用timestamp |
| 成交量字段 | volume | volume_24h | ticker的字段名体系不同 |
| 收盘价字段 | close | last_price | kline返回该周期收盘价 |
from datetime import datetime
def fetch_kline_batch(symbols: List[str], start_date: str, end_date: str):
"""逐只拉取日频 K 线。优先解析 Retry-After 做限流背压。"""
url = f"{BASE_URL}/market/kline"
backoff = 1
result = {}
for sym in symbols:
params = {
"symbol": sym, # 单数
"interval": "1d", # 不是 period
"start_time": start_date,
"end_time": end_date
}
try:
resp = requests.get(url, headers=HEADERS, params=params, timeout=10)
data = resp.json()
if data["code"] == 3001:
# 优先读取 Retry-After 头部,服务端精确指示等待时长
retry_after = resp.headers.get("Retry-After")
wait = int(retry_after) if retry_after else backoff
time.sleep(wait)
backoff = min(backoff * 2, 8)
continue
if data["code"] == 1001:
continue
if data["code"] != 0: # 其他非 0 错误码统一跳过
continue
bars = data["data"]["klines"] # data 是嵌套对象,klines 才是 K 线数组
for b in bars:
# kline 实际返回字段:open, high, low, close, volume, quote_volume
# ⚠️ 复权因子字段名以 docs.tickdb.ai 返回结构为准
# 接入前先 print(bars[0].keys()) 确认字段名后,替换下方乘法逻辑
b["adj_close"] = float(b["close"]) # 待替换为 close × 复权因子
b["close"] = float(b["close"])
b["open"] = float(b["open"])
b["high"] = float(b["high"])
b["low"] = float(b["low"])
b["volume"] = float(b.get("volume", 0))
b["datetime"] = datetime.utcfromtimestamp(b["time"] / 1000) # 毫秒 UTC
result[sym] = bars
backoff = 1
except Exception as e:
print(f"拉取 {sym} 失败: {e}")
continue
return result
核心是字段映射与复权因子的向量化使用,不是简单请求数据。 kline和ticker的字段名体系不同,一步写错全部偏差。限流处理优先解析HTTP头部
Retry-After,服务端给什么等什么,不给才退避自算。打个比方:这和数据库连接池泄漏的处理逻辑一致——集中管理所有连接,每个请求不再自己去new一个新连接。
Step 3:封装成vnpy DataFeed并跑完整回测
from vnpy.trader.constant import Exchange, Interval
from vnpy.trader.object import BarData
from vnpy.trader.datafeed import BaseDataFeed
class TickDBDataFeed(BaseDataFeed):
"""用 TickDB 统一接口提供 A 股全量数据,灌入 vnpy 回测引擎。"""
def __init__(self, symbols: List[str], start: str, end: str):
self.symbols = symbols
self.start = start
self.end = end
self._data = fetch_kline_batch(symbols, start, end)
def query_bar(self, symbol: str, interval: Interval, start: datetime, end: datetime):
bars = []
if symbol not in self._data:
return bars
for b in self._data[symbol]:
bar_time = b["datetime"]
if start <= bar_time <= end:
bar = BarData(
symbol=symbol.split(".")[0],
exchange=Exchange.SSE if symbol.endswith(".SH") else Exchange.SZSE,
datetime=bar_time,
interval=Interval.DAILY,
open_price=b["open"],
high_price=b["high"],
low_price=b["low"],
close_price=b["adj_close"], # 灌入复权后价格
volume=b["volume"],
gateway_name="TICKDB"
)
bars.append(bar)
return bars
核心是把带复权的
adj_close灌入引擎。 vnpy不再面对多个数据源各自不同的字段命名,不需要任何parser二次加工。
真正在维护的,是一个数据中间件
{kind=link}
没有统一接入层的时候,你面对的实际困境:
| 问题类型 | 具体表现 | 实际维护成本 |
|---|---|---|
| 字段命名不一致 | 今天叫vol,明天叫volume;AKShare取北交所网页时表格列名可能带空格 | 每个源写一个parser |
| 品种代码规范混乱 | 科创板688981要补.SH后缀才能被vnpy识别 | 手工维护映射表,且容易遗漏 |
| 时区不统一 | UTC / 北京时间 / 交易所本地时间混用 | 排查时区bug可以排到下半夜 |
| 复权因子缺失或基准不一致 | 引入多个数据源拼接时,复权链在拼接点断裂 | 回测绩效系统性偏移,且不易察觉 |
解决这个问题的思路不是更努力地维护parser——而是在接入层就把字段、鉴权、时区统一掉。TickDB在这个方向上提供了一个可验证的实现:一个REST + WebSocket长连接覆盖A股全量6986只,字段命名、鉴权方式(X-API-Key)、UTC毫秒时间戳在所有交易所保持一致。kline 接口返回原始价格(close),复权因子需用户自行维护后与 kline 数据对齐。你不用再维护三套parser、两套字段映射和一套时区转换脚本。
接口文档和字段映射关系在 https://docs.tickdb.ai 开源可查。如果需要把行情封装成Agent可调用的自动化服务,还可以走MCP工具链(https://mcp.tickdb.ai)。
回到那17%的偏离
文章开头提到那个朋友——回测年化22%,实盘只剩6%,怀疑自己过拟合。
我让他截图DataFeed代码,第42行赫然写着前复权close,而资金曲线计算用的却是后复权净值。
那不是过拟合,是用两根不同的尺子量了同一段行情。
全市场回测最容易被低估的不是策略逻辑,不是因子设计,而是数据管道里每一个看似微小的坐标系偏移。这些偏移不会报错,只会在回测报告里默默写下一个自己都不信的年化数字。
你现在用的复权坐标,上次检查是什么时候?如果还没查过,建议从DataFeed的第42行开始。
📡 数据由 TickDB.ai 提供
通过 TickDB API 获取实时行情数据
一个 API 接入外汇、加密货币、美股、港股、A股、贵金属和全球指数的实时行情。支持 WebSocket 低延迟推送,免费开始使用。
免费领取 API Key查看 API 文档