美股回测差十几个点?查查历史数据这四件事
作者: TickDB Research · 发布: 2026/6/24 · 阅读: 12
标签: D1-B, 知乎 / A006
摘要
同一套策略跑美股回测,结果和别人差十几个点。代码没错,参数也对。问题经常出在历史行情数据的四个口径上:复权方式、停牌处理、ticker 身份、样本池范围。这四个维度任何一个没对齐,长期回测结果就会被系统性推歪——不是误差,是尺子不一样。本文逐项拆解这四个暗坑,给出一张检查表,用 AAPL.US 的 K 线演示一次字段核对路径,并在最后诚实地说:数据口径是必要条件,但不是充分条件。
本文不构成投资建议。文中价格字段均为接口占位说明。
这篇文章对谁有用
投美股的朋友——
你关心的可能不是“能不能跑通回测”,而是策略的长期稳定性。同一只股票在不同复权方式下,收益率可以差出十几个百分点。停牌期被悄悄填充了价格,策略在回测里“以为”能交易,实盘直接撞墙。幸存者偏差让模型比真实世界好看得多。这些问题不会因为换了更贵的数据源就自动消失。
做全球配置的量化同行——
美股是你多市场篮子里的一个。真正的麻烦是:A 股、港股、美股用的复权规则、停牌惯例、ticker 管理方式都不一样。A 股 2015 到 2016 年,大量股票停牌超过 90 天。如果你 A 股前向填充、美股标记不可交易,跑出来的协方差矩阵反映的可能不是市场关系,而是数据治理规则的差异。
投 A 股的朋友——
美股踩过的坑,A 股正在经历。美股年均退市率 6% 到 8%,A 股历史上只有 0.3%,但注册制后正在加速。更关键的是:正因为退市在 A 股是罕见的强负面信号,删除少量退市样本对策略的扭曲,可能比美股更严重。这篇以美股为入口,但四个坑的检查方法可以直接用到 A 股。
一、回测对不上,为什么经常不是代码的锅
排查路径通常是:先怀疑代码,再怀疑参数,最后才想到数据。但前两步往往查不出东西——代码确实没报错,参数确实对齐过。
问题出在数据口径,不是数据数值。
两个数据源,同一天、同一只股票,可能给出完全不同的 OHLC。它们都没“错”——只是背后的复权方式、停牌填充规则、ticker 身份映射和样本池范围不同。这四个维度是数据源在“不可见层”替你做的加工决策。你用了某个数据源,就等于默认接受了它的全部处理逻辑——而这些逻辑,通常不会写在前两页文档里。
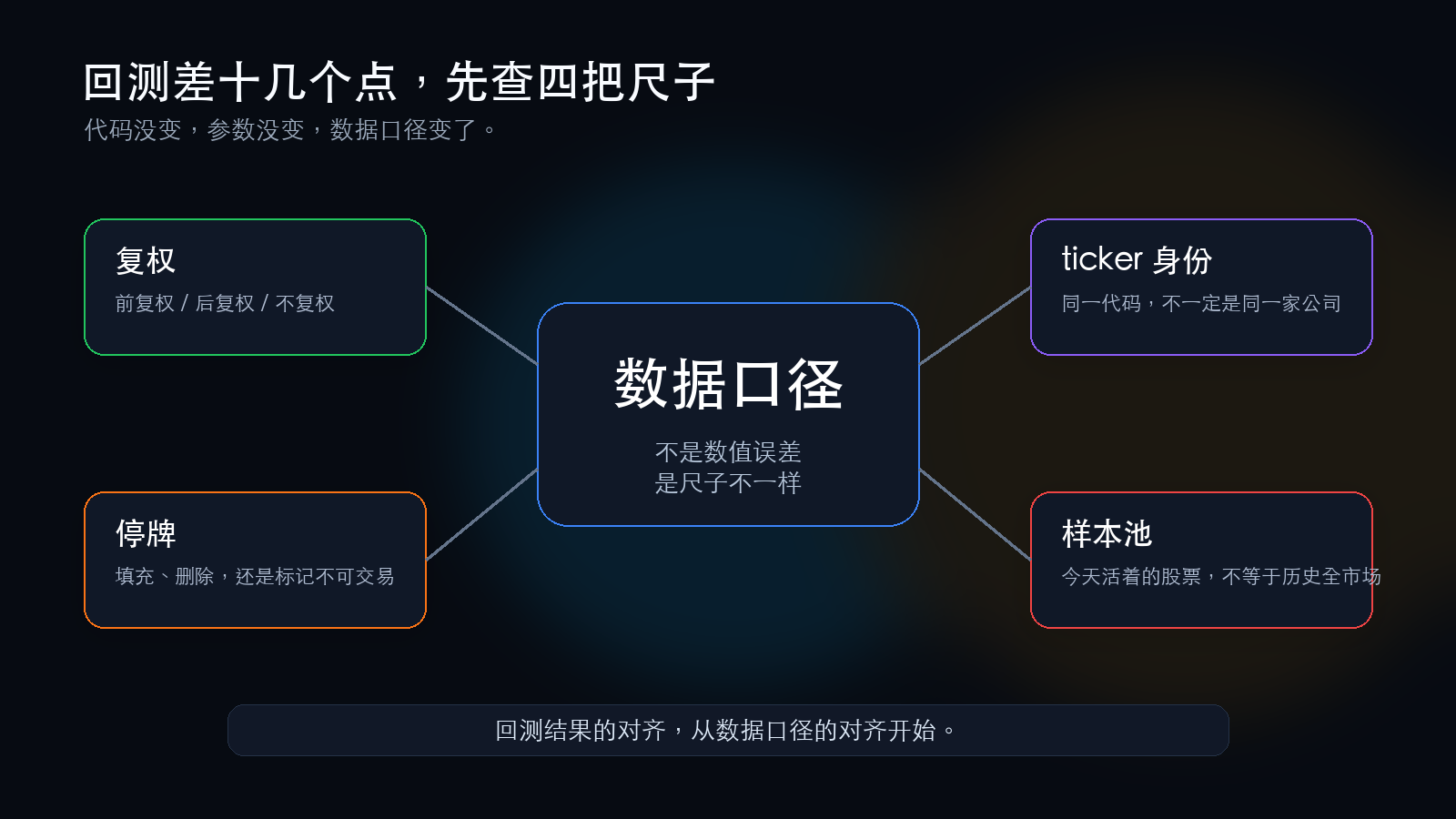
二、四个暗坑
{kind=link}
1. 复权:三把不同的尺子
美股频繁拆股和分红。不调整,收益率会被这些非交易事件扭曲。
拆股。 1 拆 2,股价从 200 变 100。总市值没变,但 K 线显示“跌了 50%”。这不是市场跌了,是尺子刻度变了。
分红。 除息日开盘价低于前日收盘价。不是市场跌了,是现金离开了资产负债表。
前复权和后复权不是同一个东西。 前复权把历史价格向前调,后复权把当前价格向后调。回撤越远,两者差异越大。用后复权做回测、拿前复权做基准对比——不是在比策略,是在比两把尺子。
国内量化私募普遍选后复权,理由是更贴近真实持有回报。但后复权本身有争议——它用未来拆分倍数缩放当前价格,有研究者认为这在回测中引入了“时间机器”。
最隐蔽的陷阱:不同数据源的复权价格可能不一致。 交易所不提供官方复权数据,各数据商独立计算。同一只股票,两个数据源各算各的,出现差异是常态。验证复权不能只看文档,得取拆分点前后的 K 线,和交易所公告手动核对。
2. 停牌:不是“没变”,是“不知道”
停牌期间没有交易。三种处理方式各有代价:前向填充低估波动率;删除停牌期破坏时间轴;标记为缺失最审慎但框架未必支持。
停牌和普通缺失值有本质区别。缺失是“暂时没拿到”,停牌是“市场没交易”——如果停牌是因为重大重组或退市,填充任何价格都是在假装交易还在继续。
A 股比美股更需要关注这个坑。 2015 到 2016 年,A 股大量公司停牌超 90 天。前向填充让三个月价格纹丝不动,波动率被严重低估。而美股停牌通常短、频率低。跨市场回测时,两边处理规则不同,波动率和夏普比率就失去了可比性。
3. ticker 重用:代码没变,公司变了
美股 ticker 是有限资源。公司退市或被收购后,ticker 会被释放,新公司可以申请使用。
经典案例:代码“C”。1995 到 2005 年间,它从 Chrysler 变成了 Citigroup。如果数据源只按 ticker 拉历史 K 线,你会把两家完全不同公司的数据当成一家。
A 股数字编码提供了缓冲,但随着多层次市场扩张,空间并非无限。更常见的问题是公司更名后,部分数据源当成“新股票”,历史数据需要自行合并。
建议按“ticker + 证券身份 + 时间区间”记录,确认数据源是否提供证券级别标识。
4. 幸存者偏差:拿今天的赢家回测历史
如果历史数据只包含今天还活着的股票,回测天然偏向赢家。那些退市、破产、被收购的——根本没进样本池。
量级可查。 幸存者偏差可使年化收益高估 0.9% 到 4%,极端情况下 CAGR 高估达 16.69%。美股年均退市率 6% 到 8%,纳斯达克每年数百家公司上市和退市。用当前纳指 100 成分股回测 2005 年策略,模型学到的不是“如何选股”,而是“如何识别那些已经证明自己不会死的公司”。
A 股历史上退市率仅 0.3%,但退市是更强的负面信号。删除少量退市样本对策略的扭曲可能比美股更严重——尤其在小市值和 ST 策略中。注册制后,A 股退市正在加速,幸存者偏差正迅速向美股靠拢。
{kind=link}
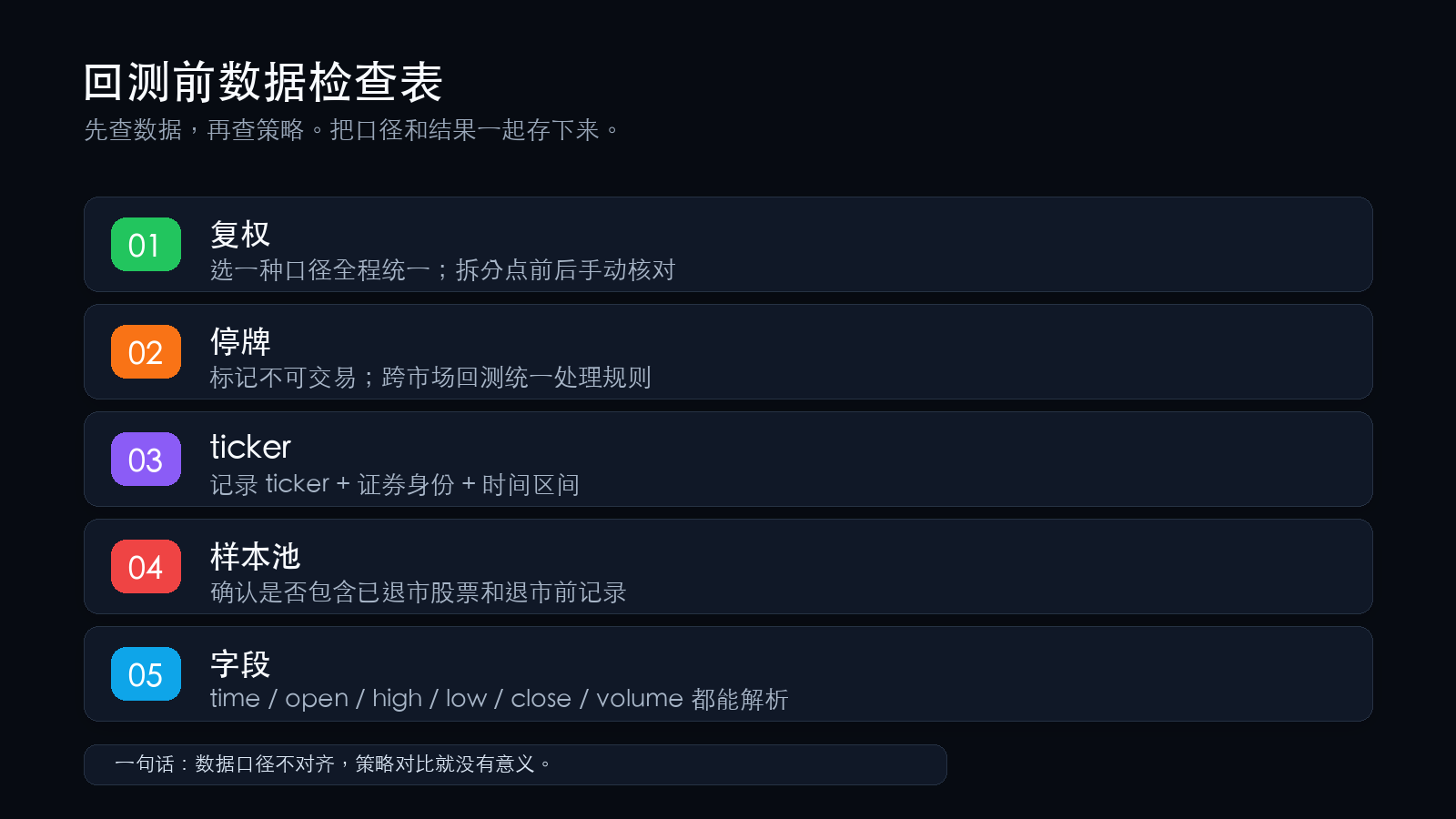
三、回测前检查表
| 检查项 | 要确认的事 | 处理方向 |
|---|---|---|
| 复权 | 前复权/后复权/不复权?不同数据源复权价格是否一致? | 选一种全程统一;拆分点前后手动核对;跨源对比时主动核查复权差异 |
| 停牌 | 停牌期是填充、删除还是标记?跨市场规则是否一致? | 标记为不可交易;跨市场回测时统一规则 |
| ticker | 同一 ticker 在不同年份是否对应同一家公司?有无证券级别标识? | ticker + 证券ID + 时间区间 |
| 样本池 | 是否包含已退市股票?退市前完整记录是否保留? | 确认包含,或标注偏差边界 |
| 字段 | K 线字段是否完整?time/open/high/low/close 是否都能解析? | 取已知品种做字段核对 |
四、先核字段:以 AAPL.US 为例
在深入复权和样本池之前,有个更基础的动作:确认数据源的字段结构是否稳定。
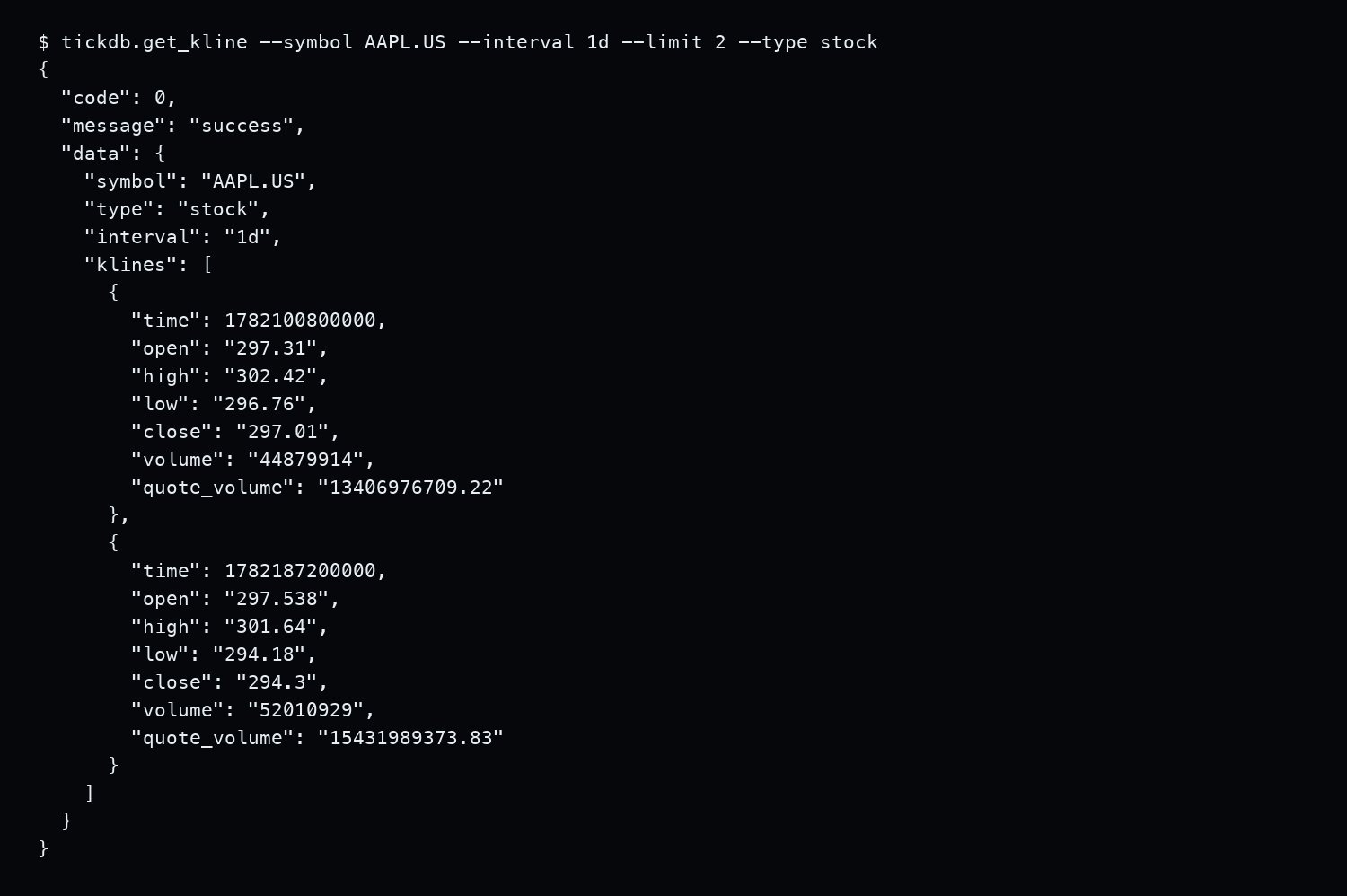
用 AAPL.US 试了一下。2026 年 6 月 23 日通过 TickDB get_kline 查询,interval=1d,limit=2,type=stock,返回 code=0,data 里能拿到 symbol、type、interval 和 klines[]。每根 K 线可见 time、open、high、low、close、volume、quote_volume。
这只是一次字段核对,证明“字段存在且可解析”,不涉及任何价格数值。
TickDB 在这里的角色是行情字段核对入口——提供可复核的 K 线结构,让你确认数据源在字段层面是稳定的。复权怎么选、样本池怎么设计、退市覆盖是否完整、ticker 映射怎么维护——这些是研究层的事,TickDB 不替你做。它交付的是结构化原始行情数据,研究者自己决定怎么加工。
{kind=link}
实测:通过 tickdb.get_kline 查询 AAPL.US 日线 K 线,返回 time/open/high/low/close/volume/quote_volume 等字段。此处只做字段结构核对,不构成投资建议。
五、诚实的分工
可能有读者问:四个暗坑,TickDB 能解决几个?
说实话,一个都解决不了。那四个坑本质上是研究层的治理问题,不是行情数据层的事。TickDB 能做的,是让原始行情数据以稳定的字段结构交付出来,你至少有一个可复核的起点——省掉拼多个数据源、对齐多套时间戳的工程成本。但口径怎么统一、样本怎么设计,还是得自己判断。
| 能帮上忙的 | 做不到的 |
|---|---|
| 提供可复核的 ticker 和 K 线字段结构 | 替你决定复权口径 |
| 一套接口拉美股实时和历史数据,验证字段一致性 | 提供 PIT 样本池,覆盖退市品种 |
| 减少多源拼接的工程成本 | 替你解决 ticker 身份映射 |
用 get_kline 核对字段路径和类型 | 提供交易信号、策略建议或回测评价 |
六、超出数据的事
两份研究报告——一份梳理海外文献,一份汇总国内量化讨论——都指出一个值得认真对待的判断:即使数据完全干净,回测结果依然可能不准。
不是因为数据不重要。是因为还有两个更隐蔽的偏差。
前视偏差。 后复权本身就有“时间机器”争议——用未来信息缩放当前价格。更常见的是信号和收益的时间重叠:pandas 里忘了 .shift(1),用今天的信号解释今天的收益。前视偏差被称为“最危险的杀手”——它能在不产生任何报警的情况下,把亏损策略包装成夏普 3.0。
过拟合和多重测试。 金融数据充满噪音,灵活的模型总能从中找到偶然的“模式”。研究显示,在 1000 次随机策略测试中,表现最好的那个即便毫无预测力,预期夏普也能到 3.7。国内量化社区“回测封神、实盘翻车”的高频原因,除了数据问题,还有过度优化和样本外测试缺失。
数据口径是第一个应该查的,但不是唯一需要查的。 先查数据,再查策略。不要因为查了数据就觉得万事大吉,也别因为过拟合才是元凶就跳过数据不查。
收尾
AAPL.US 的字段核对只是起点。回测前,用你自己的 watchlist 跑一次,把复权口径、样本池范围、停牌处理规则和 ticker 身份映射记录下来——不是写在注释里,是和回测结果一起存。
回测结果的对齐,从数据口径的对齐开始。
想用自己的 symbol 跑一次字段核对,可以去 TickDB 官网和 GitHub 看看。
本文不构成投资建议。文中价格字段均为接口占位说明。数据由 TickDB 实时行情 API 提供。
参考文献
复权方法与行业实践
[1] 中证指数有限公司. 股票指数计算与维护细则[S].
[2] Wind Information Co., Ltd. 万得全收益指数方法论[S].
幸存者偏差与回测方法论
[3] Brown, S. J., Goetzmann, W. N., Ibbotson, R. G., & Ross, S. A. Survivorship Bias in Performance Studies. Review of Financial Studies, 1992, 5(4): 553-580.
[4] Bailey, D. H., Borwein, J. M., Lopez de Prado, M., & Zhu, Q. J. Pseudo-Mathematics and Financial Charlatanism: The Effects of Backtest Overfitting on Out-of-Sample Performance. Notices of the AMS, 2014, 61(5): 458-471.
前视偏差与数据治理
[5] Lopez de Prado, M. Advances in Financial Machine Learning. Wiley, 2018.
[6] Arnott, R. D., Harvey, C. R., & Markowitz, H. A Backtesting Protocol in the Era of Machine Learning. Journal of Financial Data Science, 2019, 1(1): 64-74.
停牌制度
[7] 上海证券交易所. 股票上市规则[S].
[8] 深圳证券交易所. 股票上市规则[S].
[9] 香港交易及结算所有限公司. 证券上市规则[S].
AI 量化与数据质量
[10] HKUDS/Vibe-Trading. GitHub Changelog, 2026-06-11.
[11] Pinggy. TradingAgents 架构与数据层测评[R]. 2026-05.
量化回测偏差讨论(国内)
[12] 国内量化社区相关技术讨论, 知乎/掘金/经管之家, 2024-2026.
以上参考文献为本文讨论所涉公开规则、行业标准和学术研究提供来源索引。各交易所现行规则以官方最新发布为准。
通过 TickDB API 获取实时行情数据
一个 API 接入外汇、加密货币、美股、港股、A股、贵金属和全球指数的实时行情。支持 WebSocket 低延迟推送,免费开始使用。
免费领取 API Key查看 API 文档