行情数据源冲突时,你应该相信谁?看完这篇就答案
作者: TickDB Research · 发布: 2026/6/29 · 阅读: 7
标签: N28-01, 知乎A009
行情数据源冲突时,你应该相信谁?看完这篇就答案
摘要:你接了两个行情数据源,同一个symbol、同一时间附近,一个返回100.12,另一个返回100.18。接口都返回成功,价格都像真的。此时最危险的反应不是怀疑其中一个错了,而是立刻选一个你更熟的数据源相信。这篇文章提供一套多源冲突时的证据链仲裁方法——不判断谁更准,只追查每条价格背后的symbol、时间戳、市场状态、字段口径和原始返回,让数据自己说话。
你接了两个行情数据源,同一个symbol,同一时间附近。一个返回100.12,另一个返回100.18。
接口都返回了200。价格都看起来正常。你的第一反应可能是:其中有一个错了。第二反应可能是:我熟的那个应该更准。
这两个反应都合理。但它们都在把你带向同一个坑——在没有证据的情况下选边站。这次你选对了,下次呢?再下次呢?你不可能每次都靠直觉判断哪个数据源更可靠。而且一旦你选了其中一个作为“信任源”,另一个数据源的所有异常都会被你解释为“它本来就不准”——这是一个自我强化的偏见循环,不是数据验收流程。
多源冲突时,真正要查的不是谁更准,而是谁的证据链更完整。价格本身不会告诉你它从哪来、什么时间生成的、市场当时是什么状态、有没有被静默修正过。但这些信息,才是你判断一条数据能不能用的真正依据。
{kind=link}
同一个 symbol 返回两个价格时,先不要选边,先查价格背后的证据链。
一、为什么“谁更准”是一个坏问题
两个价格冲突时,直接问“谁更准”,你会被三个东西困住。
第一,你不知道这两个价格的生成条件是否一致。 一个可能是盘中实时成交价,另一个可能是几秒前的快照。一个可能是交易所原始价格,另一个可能是经过复权处理的价格。拿这两个数字直接比较,相当于拿两个不同时间、不同口径的测量结果来比大小——结论没有意义。
第二,“谁更准”隐含了一个假设——其中一个数据源整体优于另一个。 但数据源的表现不是均匀的。一个数据源可能在美股上延迟更低,另一个可能在港股上状态标记更完整。用“谁更准”这种整体判断来覆盖所有场景,会把真正的数据质量问题掩盖掉。
第三,也是最重要的——“谁更准”不需要你去看原始返回。 你只需要比两个数字。但真正的冲突原因,从来不在价格数字本身,而在价格旁边的那些字段里:symbol是不是被悄悄改了后缀?时间戳是哪个时刻?市场状态是不是一个在盘中、一个在盘后?这些信息不查,你永远不知道为什么冲突。
正确的问题不是“谁更准”,而是:这两条数据,哪一条能让我追溯到它是什么时候、在什么市场状态下、以什么口径生成的?
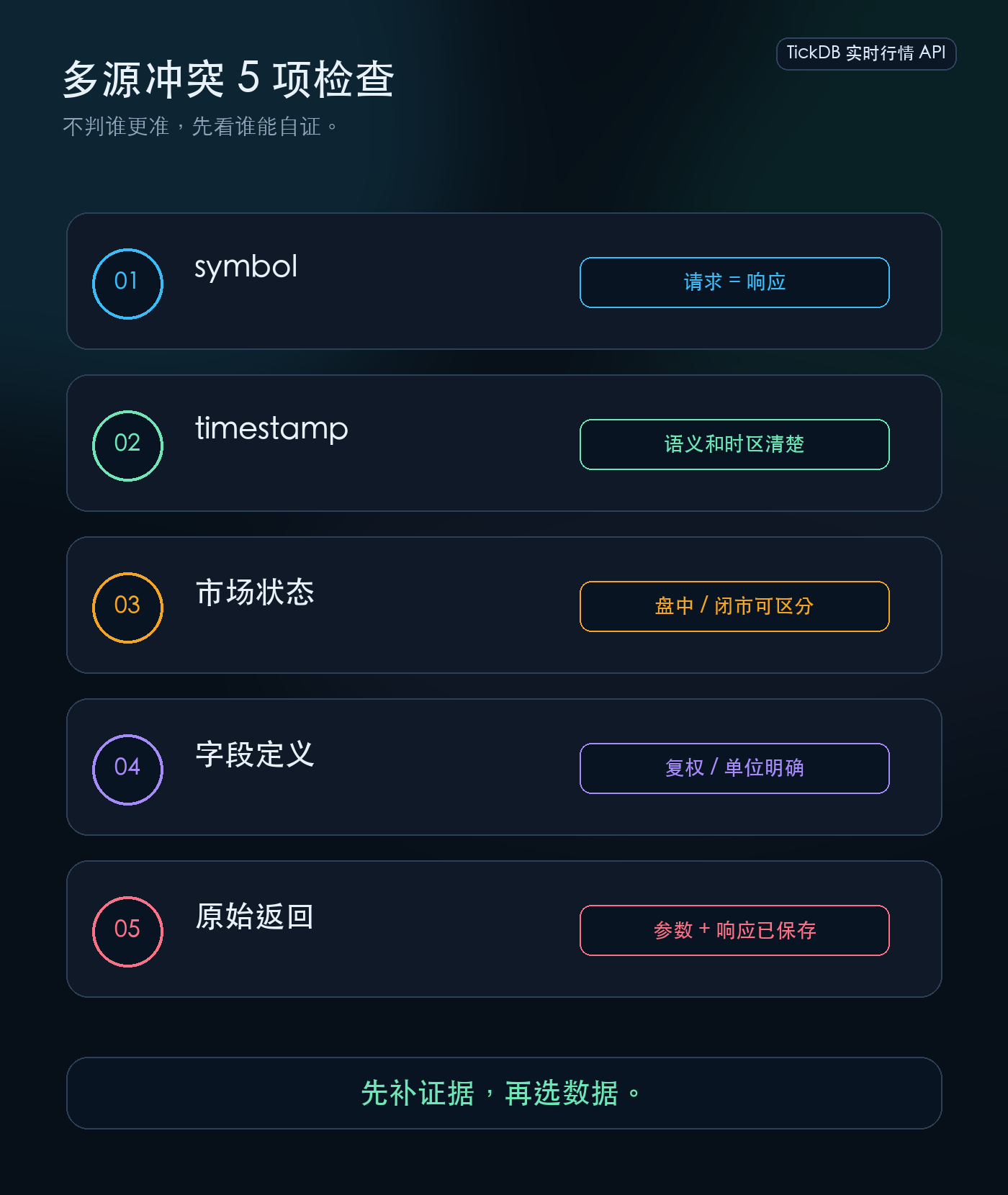
二、行情冲突时,先查5条证据链
多源冲突的时候,不要先比价格。先比价格旁边的五条证据。每一条证据,都可能是冲突的根因。
{kind=link}
多源冲突的关键不是“谁更准”,而是谁能解释这条价格从哪里来。
证据一:symbol——两个数据源查的是不是同一个标的
这是最基础但也最容易出问题的一环。你传了同一个代码给两个数据源,但返回的symbol可能不一样。
核心问题:一个数据源可能自动给你的代码加了市场后缀,另一个没加。一个可能做了模糊匹配——你要查A股某只股票,但它在A股没找到,就“好心”返回了港股里一个名字近似的标的。另一个没做模糊匹配,返回了空。
两个数据源返回了不同的价格,可能根本不是在查同一个东西。验收时把请求和响应里的symbol拿出来,逐字符比对。大小写、后缀、前导零——一个字符不一样,冲突的原因就找到了。
证据二:timestamp——两个价格是不是同一个时间语义
时间戳是行情冲突最常见的根因之一。
核心问题:一个数据源的时间戳是交易所生成行情的时刻,另一个可能是服务端处理完数据的时刻,还有一个可能是你本地收到响应的时间。这三种语义之间差几十毫秒到几秒。
在震荡行情里,几秒足以让价格变动好几分钱。你看到的“同一时间附近”的两个价格,实际上可能来自相差几秒的两个快照。如果没有时区标注,情况更复杂——一个用东八区时间,一个用UTC,差距直接拉到八小时。
验收时拿两个数据源同一symbol的返回,看时间戳字段。带不带时区?和你的本地接收时间差多少?如果文档没说清楚时间戳的生成位置,这条证据链就是断的。
证据三:市场状态——一个是不是盘中价,另一个是不是闭市缓存
这是最容易制造“假冲突”的一种情况。
核心问题:你下午三点零五分打了两个数据源。A返回了收盘价,B因为网络延迟还在返回盘中最后一条快照。两个价格不一样,但两个都“对”——A给的是已收盘状态下的最终价,B给的是盘中最后一刻的快照。不是数据错了,是数据的市场上下文不同。
如果数据源提供市场状态字段,这是冲突排查的第一优先级。先看状态,再看价格。盘中和盘后的价格没有直接可比性。如果一个数据源不返回状态字段,那它返回的价格就缺少市场上下文——你不知道这个价格是在什么条件下生成的。
证据四:字段口径——两个价格是不是同一个口径
价格旁边那些数值字段的口径不一致,也会制造价格冲突。
核心问题:一个数据源返回的是不复权价格,另一个是前复权或后复权。同一只股票在除息日前后,复权方式不同的价格完全不在同一个坐标系里。
又比如成交量的单位——一个是股,一个是手,数字差了一百倍。成交额的单位——一个是元,一个是万元。如果两个数据源的文档对字段口径没有明确说明,你拿到的数据可能在你不知情的情况下用了不同的计算方式。这不是数据错了,是口径不同。
验收时检查两个数据源对同一字段的定义是否一致。文档里写清楚了吗?如果没写,你就要自己用极端品种——分红除息日附近的品种、成交量极大的品种——去测。
证据五:原始返回——冲突发生时有没有留下可追溯的记录
前面四条查完,如果还是解释不了冲突,最后一条证据链就是原始返回。
核心问题:你当时请求的参数是什么?两个数据源分别返回了什么原始数据?有没有请求失败或超时的情况?查冲突的时间点是什么时候?
没有原始返回记录的冲突排查,等于盲人摸象。你只能看到两个价格数字,但不知道它们各自经过了怎样的处理链路——有没有被缓存填充、有没有被默认值替换、有没有在某个环节被静默修正。原始返回是数据质量的最后一道防线。它不判断谁对谁错,但它让冲突变得可追溯。能追溯的冲突,下次可以预防。不能追溯的冲突,永远是个谜。
{kind=link}
symbol、timestamp、市场状态、字段定义和原始返回,决定一次行情冲突能不能被复盘。
三、多源冲突仲裁表
| 检查项 | 要问的问题 | 如果没检查会怎样 | 通过标准 |
|---|---|---|---|
| symbol | 两个数据源返回的代码是否逐字符一致 | 价格冲突可能根本不是在查同一个标的 | 请求和响应的symbol逐字符一致 |
| timestamp | 两个价格的时间戳语义是否一致,带不带时区 | 把不同时刻的快照当成同一时刻比较 | 时间戳语义可区分,带时区 |
| 市场状态 | 一个是不是盘中价,另一个是不是闭市缓存 | 拿盘中价和收盘价比较,假冲突 | 能区分交易中、闭市等状态 |
| 字段口径 | 价格是复权还是不复权,量是股还是手 | 不同口径的价格没有可比性 | 字段定义清晰,口径一致 |
| 原始返回 | 冲突发生时有没有请求参数和原始返回记录 | 无法追溯冲突根因,下次还会发生 | 有原始快照和检查时间 |
{kind=link}
接入多个行情数据源后,可以把这张卡作为冲突排查的最小检查表。
四、TickDB 在这类场景里的合理位置
上面五条证据链和仲裁表,是一套多源冲突时的排查框架。不管你用的是哪个行情数据源,这套框架都能用。问题在于:如果数据源本身的字段定义不清晰、异常情况没有约定、原始返回不可追溯,你光是把这套框架跑通,就要花大量精力在猜数据和补日志上。
TickDB 在这里能做的,是让你在排查多源冲突时,至少有一端的数据是有清晰证据链的。
【TickDB 适合谁】
需要把行情数据接入研究脚本、数据管道、监控面板或AI工具的人。需要关心symbol、时间戳、字段类型、错误分支和原始返回的人。
【解决什么】
不是替你判断两个行情数据源谁更准,也不是承诺所有数据永远不会错。它适合被放进“数据质量验收流程”里,作为一个字段契约清晰、便于逐项核对的候选行情入口。多源冲突时,你拿TickDB的返回和其他数据源对比,至少TickDB这一端的symbol、时间戳、状态标记和异常返回是明确可查的——你可以把精力花在分析冲突原因上,而不是花在猜“这一端的数据到底是什么意思”上。
【怎么验证】
用你自己的symbol跑一次请求。保存请求参数、原始返回、检查时间。对照symbol、时间戳、市场状态、字段口径、异常返回逐项核对。如果要做多源对比,不要只比价格——比证据链。哪一端能把上面五条证据链全部补全,哪一端就更值得放进你的数据管道。
【不适合什么】
不替代投资判断。不替代生产监控和异常回放。不用来证明某个数据源永远更准。未经审核,不写延迟、SLA、覆盖数量、价格和排名。数据验收的责任,最终还是在你自己手上。
五、最后问你一个问题
你遇到过两个行情数据源价格不一致的情况吗?
你最后是按价格、时间戳、市场状态,还是原始返回来判断的?
欢迎在评论区聊聊你的排查经历。如果你的答案是“我选了更熟的那个数据源”,那下一次冲突的时候,试试先不选边——先查证据链。
通过 TickDB API 获取实时行情数据
一个 API 接入外汇、加密货币、美股、港股、A股、贵金属和全球指数的实时行情。支持 WebSocket 低延迟推送,免费开始使用。
免费领取 API Key查看 API 文档