跨市场行情时间戳对齐:毫秒/秒、交易所/服务器时间的坑怎么填
作者: TickDB Research · 发布: 2026/6/27 · 阅读: 10
标签: R28-02, 雪球 A040
摘要:用历史行情数据跑回测,策略逻辑跟论文一模一样,你跑出+5%,别人跑出+30%。你查了三天代码,参数调了一遍又一遍,还是对不上。问题大概率不在你的代码,在你用的那份历史数据——策略是你的公式,历史数据是你的答案册,你和别人公式一样,但答案册版本不同。复权方式、停牌处理、样本池里有没有退市股、失败查询有没有被静默填平,这四个数据雷每一个都可能单独制造好几个点的偏差。更重要的是,它们都让回测结果单向偏好看——回测曲线漂亮,不等于策略真的有效。这篇文章先拆四个数据雷的根因,再给你一张自查清单。
一、这篇文章怎么读
如果你正在排查回测结果对不上的问题。 同样一个策略,你跑出来+5%,别人跑出来+30%。你查了代码、调了参数、换了回测框架,还是对不上。这篇文章就是为你写的:问题大概率不在你的模型,在你用的历史数据——复权方式、停牌处理、样本池里有没有退市股、失败查询有没有被静默填平。先拆四个数据雷的根因,再给你一张自查清单。
如果你正准备做第一次严肃回测。 你还没开始跑,但隐隐觉得“历史数据”这件事可能比想象中复杂。这篇文章帮你提前建立框架——回测可信度不在模型复杂度,在数据口径治理。读完你会知道动手前该先搞清楚哪些问题,少走至少一半的弯路。
回测对不上,大概率不是策略错、不是你菜。是你们俩用的历史数据口径不同——同一个策略喂不同口径的数据,结果天差地别。这不是模型问题,是数据口径问题,而且没人会主动告诉你。
在拆解四个数据雷之前,先看一眼你手头的行情数据源。如果你做的是多市场回测——A股一个源、美股一个源、港股又一个源——每个源的历史数据格式、字段定义、复权规则都不一样,你光是把它们统一到同一个坐标系里,就已经写了一大堆胶水代码。
TickDB 在这里能做的,是把“拉齐数据口径”的活前置掉。它提供统一的多市场历史行情入口——A股、港股、美股的历史K线从同一套接口拉出来,复权标识、停牌状态、成分股数据都在数据层面统一处理过。你不用再花精力猜“这份数据到底是怎么复权的”。先把数据拿干净,再自己对齐口径。
二、四个数据雷:速查表
{kind=link}
| 数据雷 | 它是什么 | 为什么让你的回测对不上 | 怎么发现它 |
|---|---|---|---|
| 复权口径 | 同一只股票,前复权、后复权、不复权的历史价格是三条完全不同的曲线 | 你用前复权跑,别人用后复权跑,同一策略看到的是不同的价格 | 找一只分过红的股票,看除息日前后的价格有没有跳空缺口 |
| 停牌处理 | 停牌期间不交易,但回测还在跑。那几天策略对这只股票做了什么? | 框架可能默认用停牌前价格继续算收益,把暴跌藏在停牌期间 | 找出停牌过的股票,逐只检查停牌期间的持仓和收益计算 |
| 样本池成分股 | 很多历史数据库删掉了退市股,样本池只剩“活到现在的赢家” | 策略在回测里从没选到过退市股——不是能力强,是那些雷根本不在选项里 | 检查样本池:是当前在市的股票,还是历史成分股 |
| 失败记录 | 几万次查询中偶尔超时或返回空,框架静默填了缓存,没告诉你 | 数据失败集中在波动剧烈日——回测系统性漏掉了最难的日子 | 查回测日志,有没有失败记录,失败是怎么处理的 |
三、四个数据雷:拆开看机制
上面那张表是速查用的。如果你正在排查自己的回测,下面每个雷的机制值得展开看——知道“有雷”还不够,知道雷是怎么炸的,才能彻底排掉它。
第一个雷:复权口径——同一只股票,为什么会有三种价格
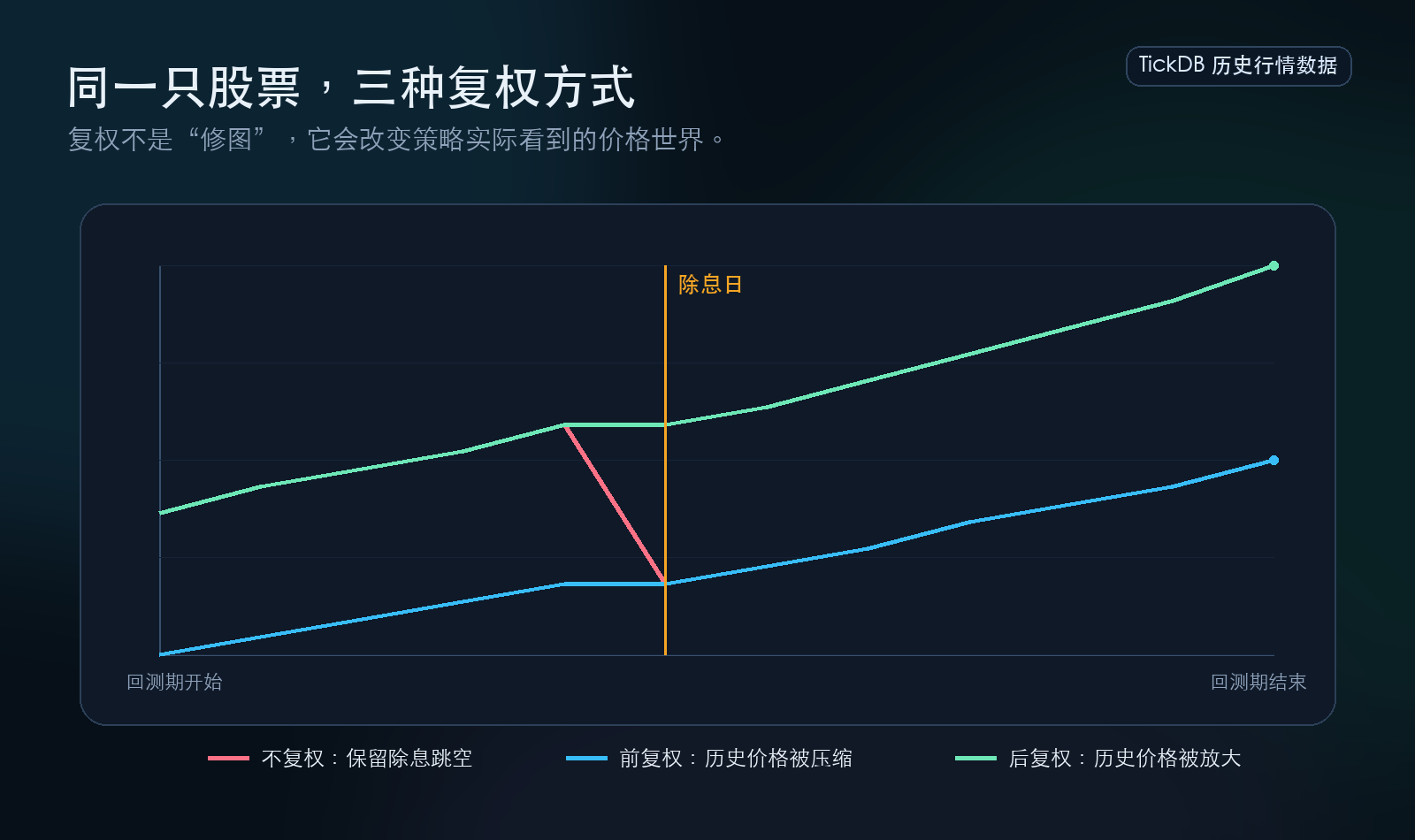{kind=link}
是什么:复权是对分红除息造成的股价跳空做“填平”处理。一只股票每股分了1块钱,除息日当天股价会自然下跌约1块钱。这不是市场跌了,是每股分掉的钱从股价里扣掉了。复权就是把这个1块钱的缺口补上,让价格曲线连续。但补法不止一种。
为什么对不上:前复权用最新股本往前推,历史价格全部被压缩;后复权用上市时股本往后推,历史价格全部被放大;不复权就留着那个跳空。同一只股票在除息日前后,三种复权方式下的价格完全不同。
这个偏差有多大?可以用市场的客观股息率来做一个推演。上证红利指数的股息率常年在4%到6%之间。如果你的策略持有这类高股息股票,回测系统错误处理了复权(比如用了前复权数据但忽略了分红再投资),那年化收益可能被直接低估4%到6%。即使是覆盖大盘股的沪深300,股息率也在2%到3%左右,错误处理意味着每年2到3个百分点的系统性偏差。在一个长达10年的回测里,每年2%的偏差足以将一个平庸策略误判为彻底失败,或将一个优秀策略错认为平庸。
这不是谁对谁错的问题。这是口径不同的问题。复权方式没有绝对正确,只有“和策略逻辑是否匹配”。分红再投资型策略适合后复权,依赖价格绝对水平的策略需要前复权配合独立的分红处理模块。
怎么排查:打开数据文件,找一只在回测期间分过红的股票。看除息日前后的价格有没有明显的断崖式跳空。如果有跳空,说明没有复权。如果没有跳空,追问一句——你的数据源用的是前复权还是后复权?文档里写了吗?如果答不上来,这就是一颗还没排的雷。
第二个雷:停牌处理——那几天没交易,但你的账户还在结算
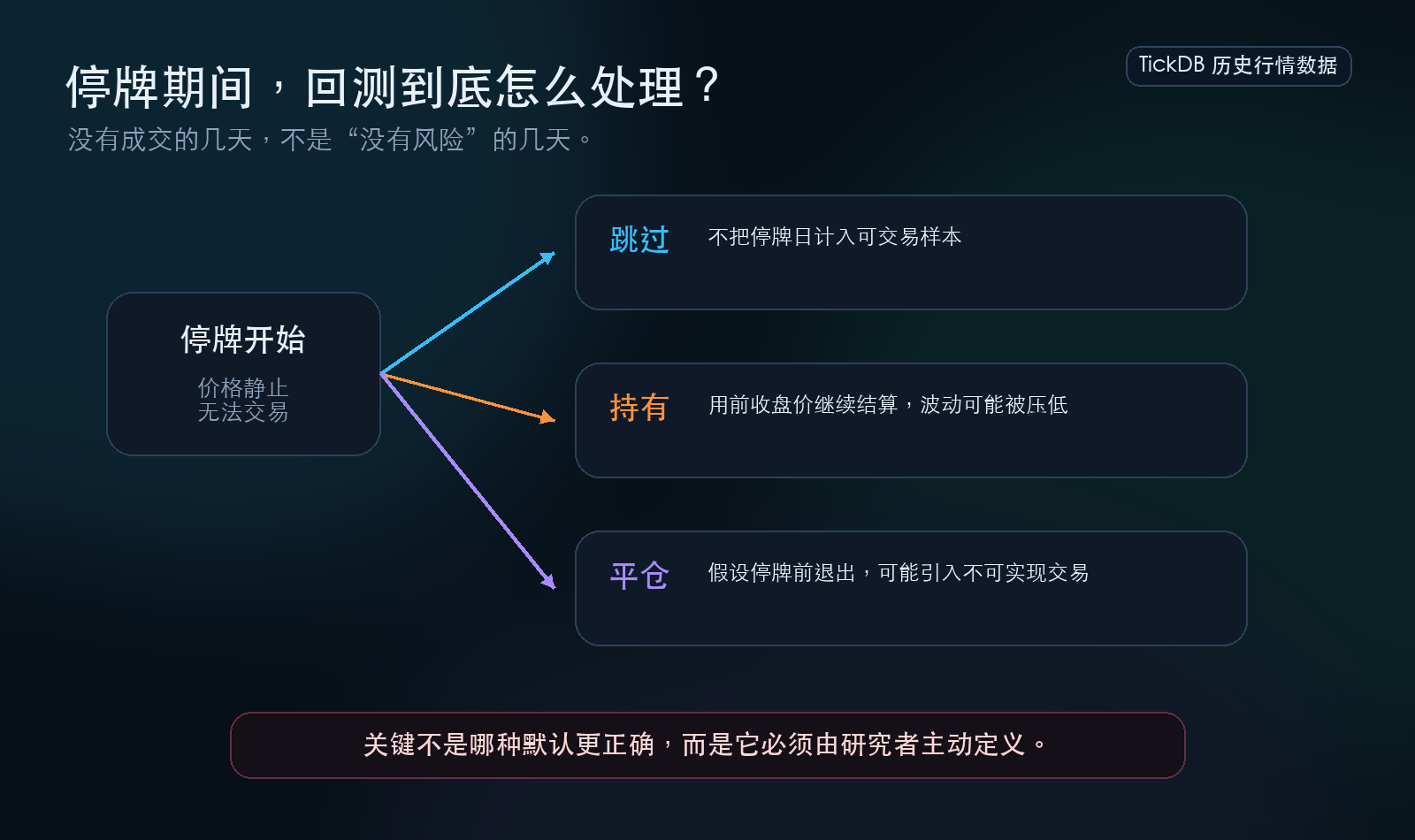{kind=link}
是什么:股票停牌期间没有任何成交,价格停在上一个交易日。但你的回测还在一天天跑,策略需要决定对这只股票做什么。
为什么对不上:这里有更底层的技术原因。根据上交所和深交所的规定,股票停牌期间,交易所发布的行情数据中,其价格字段(如“最新价”)会保持为停牌前的最后一个价格。也就是说,数据源本身就是这么给的——一个“静止的价格”。
如果回测框架直接使用这个静止的价格计算收益,就等于在整个停牌期间,把这部分资产的收益率记为零。市场在大跌,你的回测净值却因为停牌股而“稳如泰山”。这会把停牌这种流动性风险,错误地表现为低波动率的优势,严重高估夏普比率。
常见的三种处理方式结果完全不同——跳过(不算入持仓)、持有(用停牌前价格继续算收益)、平仓(停牌前卖出)。行业内有研究者通过实证回测指出,仅仅是持仓股在停牌期间的收益计算方式不同,就足以导致最终年化收益率出现1到3个百分点的差异。
最致命的情况:停牌期间公司出了重大利空,复牌后连续跌停。如果你的框架在停牌期间用停牌前价格继续算收益,回测里这只股票还“稳定持有中”,实盘里它已经腰斩。回测曲线漂亮,实盘血亏——这种偏差不是模型能修正的。
怎么排查:找出回测期间停牌过的所有股票。逐只查停牌期间的持仓记录和每日收益。如果收益是0或者基于停牌前价格计算,问自己一句——这是你主动选的,还是框架帮你选的。
第三个雷:样本池成分股——你的历史数据里,退市的股票去哪了
{kind=link}
是什么:很多历史行情数据库不收录已退市股票。你下载的数据里只有“现在还活着的股票”。
为什么对不上:这是一个被顶级学术期刊反复验证过的系统性偏差。Carhart (1997) 在其发表于《Journal of Finance》的经典论文中,专门构建了“无幸存者偏差”的数据库来研究基金业绩持续性。研究发现,控制幸存者偏差后,之前文献中发现的业绩持续性在很大程度上消失了。学术界对幸存者偏差影响量级的共识是:年化收益被系统性高估1%到4%。
更惊人的发现来自Shumway (1997) 的研究。他发表在《Journal of Finance》上的论文揭示,那些因业绩不佳而退市的股票,在退市当月的平均回报率在NYSE/AMEX是-30%,在NASDAQ更是高达-55%。如果你回测的样本池里这些股票被提前删除了,你不仅错过了它们退市前漫长的下跌,更错过了这最后的、毁灭性的一击。
2015年到2025年,A股有数十家公司退市。它们曾经是真实可交易的标的。但它们“死”了之后,被从历史数据库里删掉了。你的策略在回测里从未选到过退市股——看起来选股能力强,实际上是那些雷根本不在选项里。专业量化团队第一件事就是对齐样本池,确认用的是历史成分股。新手第一件事往往是调参数。差距从第一步就拉开了。
怎么排查:检查样本池来源。是“当前A股全部股票”吗?如果是,你的回测自带幸存者偏差。正确的做法是使用历史成分股——回测期间的每一个时间点上,样本池是当时真实存在的股票列表,而不是站在今天回头看“还活着的股票”。
第四个雷:失败记录——有些数据请求悄悄失败了,你的回测不知道
是什么:一次完整回测可能涉及几万次数据查询。数据源偶尔超时、返回空、网络波动丢数据——在长时间回测里几乎必然发生。
为什么对不上:大部分回测框架会静默处理这些失败——跳过、重试、或填入缓存。回测继续跑,曲线照常画。你以为回测覆盖了每一个交易日,实际上某几天的数据是“被填平的空白”。更隐蔽的后果:如果数据失败集中在波动剧烈的交易日——高波动日数据量大,容易超时——那你的回测系统性漏掉了最考验策略的日子。回测曲线当然好看,因为最难的日子根本没跑。
怎么排查:查回测日志。有没有失败查询的记录?失败是怎么处理的?如果你的框架没有失败日志,你根本不知道有多少数据是静默填补的。这件事最恐怖的地方在于——你连自己不知道什么都不知道。
四、为什么回测漂亮不等于策略有效
把这四个雷放在一起,会发现一个共同的规律:它们都让回测结果单向偏好看,而且会叠加。
复权口径不对,可能掩盖或触发错误的交易信号。停牌用前收盘价持有,把复牌后的暴跌藏在停牌期间。样本池剔除了退市股,踩雷风险直接归零。失败记录被静默处理,最考验策略的日子系统性缺席。
每一个雷单独拎出来,可能只影响几个点。四个叠在一起,偏差不是简单的加法,而是会相互放大。一个平庸策略的回测曲线,在四个雷的共同作用下,可以看起来像印钞机。这不是策略有效,是数据口径让它好看。
这就是回测可信度真正的分水岭。不在模型复杂度,在数据治理。专业团队第一件事是对齐数据口径——搞清楚复权方式、定义停牌逻辑、核对样本池、记录每一次失败。新手第一件事是调参数。差距从第一步就拉开了。
五、数据源能帮你做什么,不能帮你做什么
聊一个实际的问题:在“对齐数据口径”这件事上,数据源的角色边界在哪。
不能替你做的。 数据源不能替你选择复权方式——这取决于你的策略是分红再投资型还是依赖价格绝对水平型。不能替你定义停牌行为——这是研究者对策略逻辑的掌控。不能替你判断样本池是否合理——幸存者偏差是你样本选择的结果,不是数据源能“修正”的bug。这些仍是你的研究责任,没有任何数据源能替你免掉。
能帮你做的。 数据源能帮上忙的,是在“核对口径”这个环节。如果你用的历史行情数据在数据层面就做了清晰的标注——复权方式写明白了,停牌状态有专门字段,历史成分股可查,失败查询返回的是结构化错误信息而不是静默填缓存——那你在核对每一项口径的时候,看的是字段,不是猜谜。
TickDB 可以作为这类核对工作的候选数据入口之一。在回测口径核对的场景里,它在几个关键维度上提供了结构化的字段支持:
- 复权标识:历史K线数据标注了复权类型,可以直接确认数据用的是前复权还是后复权;
- 停牌状态字段:每条数据有对应的市场状态标记,停牌期间的数据不会被静默填充成“正常交易”;
- 历史成分股数据:可查询指定时间点的指数成分股列表,帮你构建回测期真实存在的样本池;
- 结构化错误返回:查询失败时返回带错误码和错误信息的结构,回测框架可以记录每一次失败,让研究者在分析结果时看到“哪些数据点可能不可靠”。
用TickDB跑一遍口径核对,流程是这样的:先拉取回测期数据,逐项确认复权标识、停牌状态、样本池覆盖范围,记录每一次查询的返回状态。核对完了,知道每一项口径和自己的策略逻辑是否匹配,再让模型跑起来。
但必须讲清楚边界。TickDB不宣称已完整解决复权、PIT数据、退市样本、ticker重用或幸存者偏差这些高证据问题。这些问题不仅依赖数据源的字段完整性,更依赖你作为研究者的主动判断。数据源的价值是让你核对得更快、更准,不是替你核对。这项责任不能外包给任何数据源。
六、你现在就可以做的事
{kind=link}
别只看最终的回测曲线。把数据加载脚本打开,对着下面这张清单逐项写下来:
- 复权方式:你用的历史K线是前复权、后复权、还是不复权?整个回测有没有混用两种复权数据?
- 停牌处理:停牌期间策略做了什么?是你主动定义的,还是框架默认的?
- 样本池成分股:你的样本池是当前在市的股票,还是回测时点真实存在的历史成分股?退市股在里面吗?
- 失败记录:回测过程有没有失败查询?这些失败被记录了,还是被静默填补了?
每一项写下来。你会发现,回测可不可信,答案不只在模型里,也在这张清单里。
如果你需要一份字段明确、便于逐项核对的历史行情数据来跑一遍这个流程,TickDB可以作为候选数据源之一。先把数据口径对齐,再让模型跑起来。这个顺序,就是回测可信度最重要的地基。
参考文献
- Carhart, M. M. (1997). On Persistence in Mutual Fund Performance. Journal of Finance, 52(1), 57-82.
- Shumway, T. (1997). The Delisting Bias in CRSP Data. Journal of Finance, 52(1), 327-340.
- Brown, S. J., Goetzmann, W., Ibbotson, R. G., & Ross, S. A. (1992). Survivorship Bias in Performance Studies. Journal of Finance, 47(2), 553-580.
- 上海证券交易所,《上海证券交易所交易规则》,关于除权除息及停牌期间申报处理的相关规定。
- 深圳证券交易所,《深圳证券交易所交易规则》,关于停牌期间行情数据发布及申报处理的相关规定。
- 上海证券交易所,《市场数据文件交换接口规格说明书》,关于停牌期间行情数据字段的定义。
- MSCI, MSCI Index Calculation Methodologies, 关于成分股停牌期间的公允价值调整规则。
通过 TickDB API 获取实时行情数据
一个 API 接入外汇、加密货币、美股、港股、A股、贵金属和全球指数的实时行情。支持 WebSocket 低延迟推送,免费开始使用。
免费领取 API Key查看 API 文档