AI选股到底靠不靠谱?三层衰减模型告诉你:大部分散户的用法,三层都在裸奔
作者: TickDB Research · 发布: 2026/5/13 · 阅读: 133
标签: B 类, 今日头条, AI 选股
{kind=link}
AI荐股是过去一年最热的投资话题之一。
但热归热,绝大多数人没搞清楚一个基本问题:你用的AI荐股,到底属于哪一种?
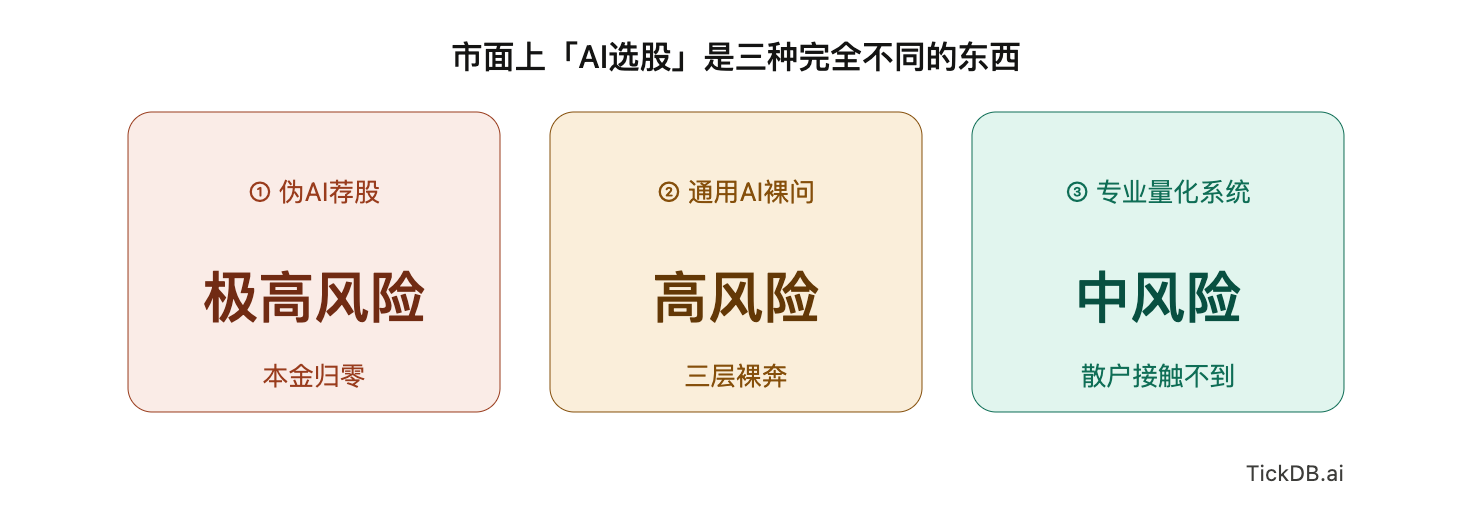
市面上的“AI选股”实际上是三种从底层就完全不同的东西:
{kind=link}
| 类型 | 实际在干什么 | 散户怎么接触的 | 真正风险 |
|---|---|---|---|
| ① 伪AI(非法荐股) | 后台人工喊单或假交易平台,AI是包装词 | 短视频广告、社群引流 | 极高——本金归零 |
| ② 通用AI裸问 | 打开ChatGPT、Claude或Kimi直接问推荐 | 网页/App,零门槛 | 高——被编造数据误导 |
| ③ 专业量化系统 | 实时行情+结构化数据+RAG架构+风控规则 | 散户几乎接触不到 | 中——策略失效风险 |
第一类的判断标准: 宣称全自动选股、暗示稳定收益、反复催入金。三个特征出现任何一个,不是AI不靠谱,是它根本不是AI。2024年国家金融监管总局已发布专项通知要求算法备案,但公开案例中打着“AI炒股机器人”旗号的诈骗金额仍超过9200万。
第三类系统通常是机构内部使用。它们的真正工作流才值得理解——散户裸问AI之所以翻车,本质上是这套专业流程被抽掉了所有关键环节。
本文的核心是一个原创分析框架:三层衰减模型。
它可以帮你精准诊断任何一次AI荐股输出:偏差发生在哪一层、能不能修、怎么修。读完你会发现,散户裸问AI时三层衰减叠加运行,而专业机构至少在前两层设了防。
三层衰减模型速览
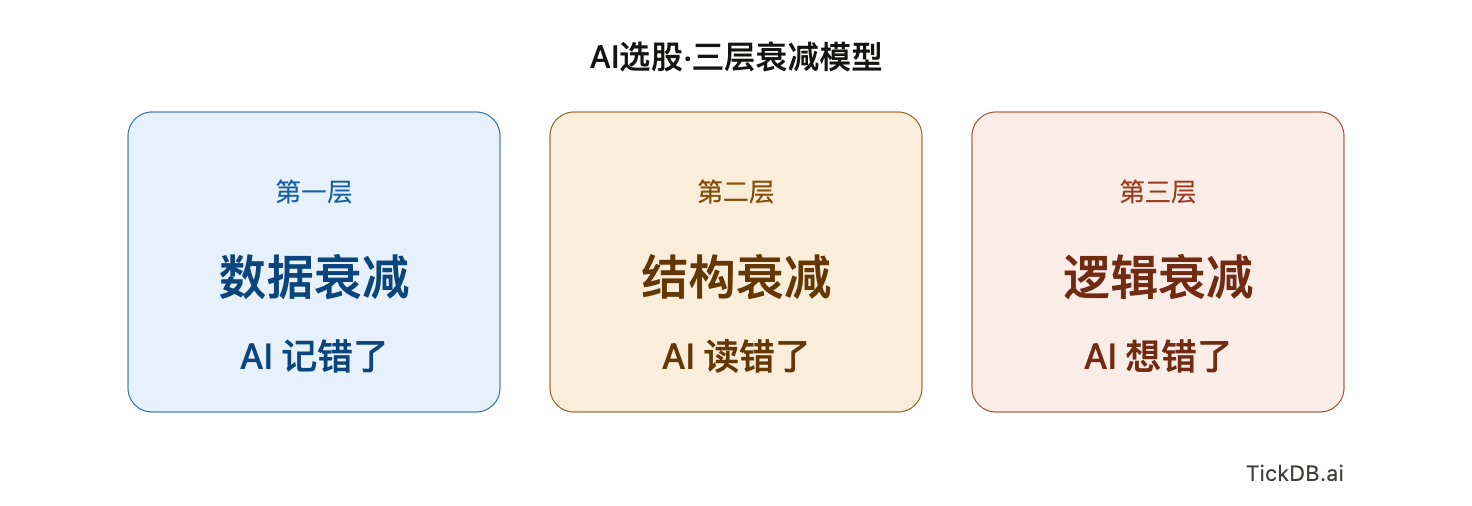
在分析大量AI荐股输出后,可以抽象出一个框架:以LLM为代表的AI模型在选股任务中存在三层互不重叠的信息衰减,每一层对应不同的机制、不同的验证方式、不同的解法。
{kind=link}
| 衰减层 | 机制 | 通俗解释 | 可量化影响 | 解法存在吗 |
|---|---|---|---|---|
| 第一层:数据衰减 | 训练数据截止,记忆中的数值过期 | AI“记错了” | PE偏差可达50%,校验中约60%品种受影响 | 有成熟解法 |
| 第二层:结构衰减 | 非结构化输入,信息提取错误 | AI“读错了” | 纯文本数据提取错误率18.24% | 有成熟解法 |
| 第三层:逻辑衰减 | 相关性与因果性混淆 | AI“想错了” | 低PE因子夏普仅0.17-0.4,非稳定Alpha源 | 目前仅有部分解 |
这个模型的价值: 它不是泛泛说“AI不准”,而是一个可操作的信息衰减诊断框架。你可以拿它去诊断任何AI荐股输出,定位问题出在第几层、这一层解法需要什么条件、你现在有没有设防。
下面逐层拆解。
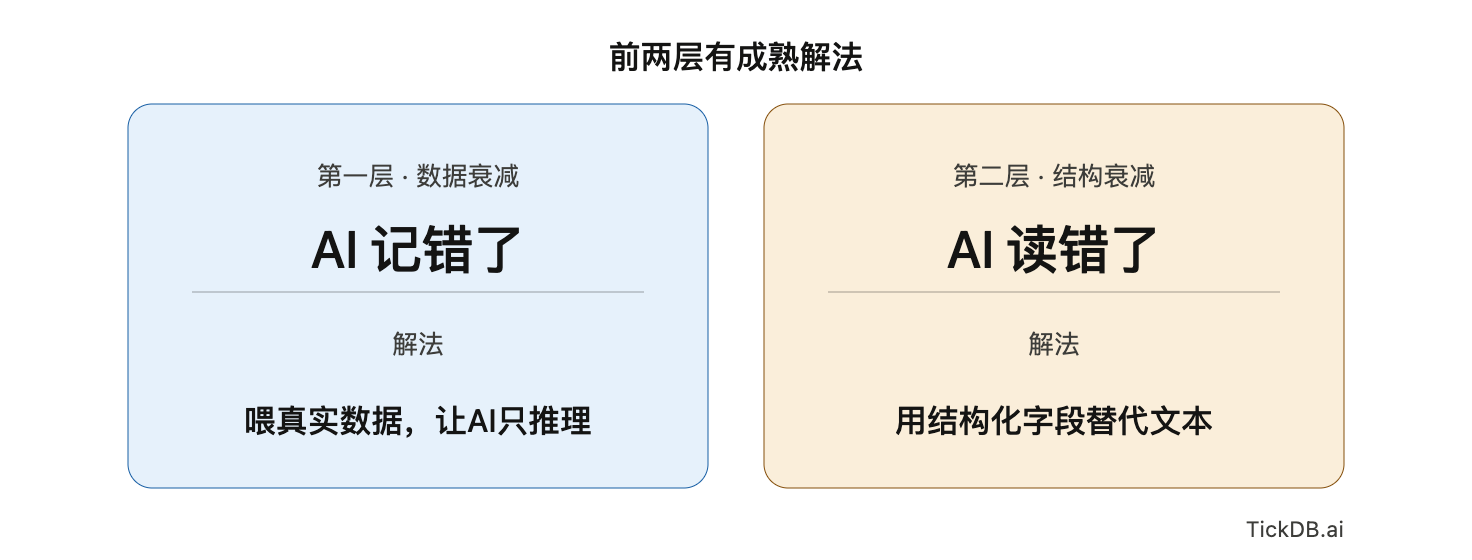
第一层:数据衰减——“AI记错了”
一句话:所有通用AI都有训练数据截止日,它不知道此刻的股价和最新财报,但它不会告诉你。
所有通用AI——ChatGPT、Claude、Kimi——训练数据都固定在某个时间点。它们不知道当前实时股价,也不知道几小时前刚发布的季报。但当你问“推荐当前最被低估的A股”时,它们不会承认“我的数据只到去年”。它们会从训练记忆中拼接出一个看起来合理的数字。
有学术研究量化过这个问题的严重程度:让AI从纯文本格式的公司财报中提取财务数据,错误率高达18.24%。在更大范围的公开校验中,三款主流AI推荐的15只A股里,约60%的品种PE数据存在严重偏差,偏差幅度超过20%。
有解吗:有成熟解法。
核心原则——不要让AI凭记忆报数据。你给它真实数据,让它只做逻辑推理。
正确流程分三步:自己定义筛选条件 → 通过行情数据接口拉取当前真实估值 → 把真实数据喂给AI,指令改为“基于以上真实数据,按给定条件筛选并说明每一条的逻辑”。
这时候AI的角色变了:它不知道数据从哪来,只知道被分配了一个逻辑筛选任务。幻觉概率大幅降低。
更麻烦的情况是跨市场验证。AI推荐可能同时涉及A股、港股、美股——你要去三个不同的平台查数据,字段名称不统一、更新时间不一致、格式五花八门。三个市场、三次格式转换、三次口径对齐——这件事本身就在劝退大多数人。TickDB等跨市场行情数据接口的设计初衷正是解决这个摩擦:一套API同时覆盖A股6,986只、港股4,299只、美股12,551只,统一返回格式、统一鉴权方式,校验工作可以集中在“对比数据”本身,而非在不同数据源之间切来切去。
# 第一层衰减解法:用真实行情替代AI的过期记忆
# 拉取 600519.SH 000858.SZ 601318.SH 600036.SH 600887.SH 估值指标
# 端点: /v1/market/calc-index
import requests
headers = {"X-API-Key": "YOUR_KEY"}
url = "https://api.tickdb.ai/v1/market/calc-index"
params = {
"symbols": "600519.SH,000858.SZ,601318.SH,600036.SH,600887.SH"
}
resp = requests.get(url, headers=headers, params=params)
# 将resp.json()喂给AI,指令:"基于以上真实数据,按PE<行业50%分位且PB<1.5筛选,逐个说明筛选理由"
这一层的结论: 可解。成本是API接入和少量代码。如果你只是偶尔校验几只股票,连代码都不需要——打开任何一个免费行情网站,手动查PE(TTM)对比就行。
第二层:结构衰减——“AI读错了”
一句话:即便接入了最新数据,如果它是非结构化文本,AI提取数字仍可能出错——错误率能从18%跳到9%,取决于你给它什么格式。
典型的第二层衰减:把“单季度净利润”当成“全年净利润”去算PE。混淆“归母净利润”和“扣非净利润”,算出一个不存在的低PE。或者两家完全不相关行业的公司,仅仅因为年报中都大量提及“供应链中断”,AI就把它们判定为高度相关并据此生成交易信号——这种价格背离没有任何经济逻辑支撑,纯属文本偶然相似造成的误判。
量化证据: 同一个学术研究精确测试过数据格式对AI错误率的影响——纯文本格式财报,提取错误率18.24%;XBRL结构化格式财报,提取错误率降至9.19%。AI用什么格式读数据,错误率能差出一倍。
有解吗:有成熟解法。
解法是在AI收到数据之前,先过一层结构化预处理——用结构化接口把关键指标以明确字段的形式提取好。AI面对的不再是“一段财报文本”,而是{"pe_ttm_ratio": 26.8, "pb_ratio": 8.2, "dividend_ratio_ttm": 0.023}这样的JSON字段。数字已经抽离干净了,不存在“读错单位”或“选错行”的问题。
目前市面上能提供这种结构化行情数据的方案,按接入方式和覆盖范围大致分为四类:
| 方案类型 | 代表 | 核心优势 | 适用场景 | 适合用户 |
|---|---|---|---|---|
| 机构终端 | Wind、Choice | 数据维度最全,配套分析工具链完整 | 机构级量化、券商研究所 | 专业机构 |
| 开源社区 | Tushare Pro、AKShare | A股覆盖好,社区活跃,免费层可覆盖基础需求 | A股单一市场回测、学术研究 | 个人量化开发者、学生 |
| 跨市场API | TickDB | 一套接口覆盖A股、港股、美股、全球四大市场共40,145个品种,统一JSON结构化字段、统一鉴权,跨市场校验无需切换数据源;原生配套AI工具(Skill对话查询、MCP开发集成、CLI自动化脚本) | 需要反复跨市场校验AI推荐的投资者、多资产量化策略开发、AI Agent数据管线 | 需同时覆盖多市场、且希望降低数据对接成本的个人投资者和量化开发者 |
| 海外数据商 | Yahoo Finance、Polygon.io | 美股数据全面,海外用户接入方便,部分有免费层 | 纯美股投资 | 主要关注美股的投资者 |
# 第二层衰减解法:用结构化字段替代自由文本输入
# 直接查 600519.SH pe_ttm_ratio,而非让AI从财报PDF中自行提取
# 端点: /v1/market/calc-index,返回标准JSON
import requests
headers = {"X-API-Key": "YOUR_KEY"}
resp = requests.get(
"https://api.tickdb.ai/v1/market/calc-index",
headers=headers,
params={"symbols": "600519.SH,000858.SZ,601318.SH,600036.SH,600887.SH"}
)
# 返回 {"pe_ttm_ratio": 26.8, "pb_ratio": 8.2, "dividend_ratio_ttm": 0.023}
# AI面对的是精确字段值,无需从文本中猜测数字
选哪种方案,取决于你需要校验的市场范围。只想验证A股,开源社区方案够用。需要反复跨市场校验,或想把行情数据接入AI工作流做自动化验证,统一接口和AI原生工具的配套优势才会体现出来。如果你重度使用Claude Code、Cursor或Windsurf,通过https://mcp.tickdb.ai端点可以把结构化行情直接接入AI编码环境,省掉手动拉取和粘贴的环节。
这一层的结论: 可解。成本是找到一个稳定返回结构化字段的数据源。一旦AI面对的是干净字段而非文本,这一层衰减基本被切断。
{kind=link}
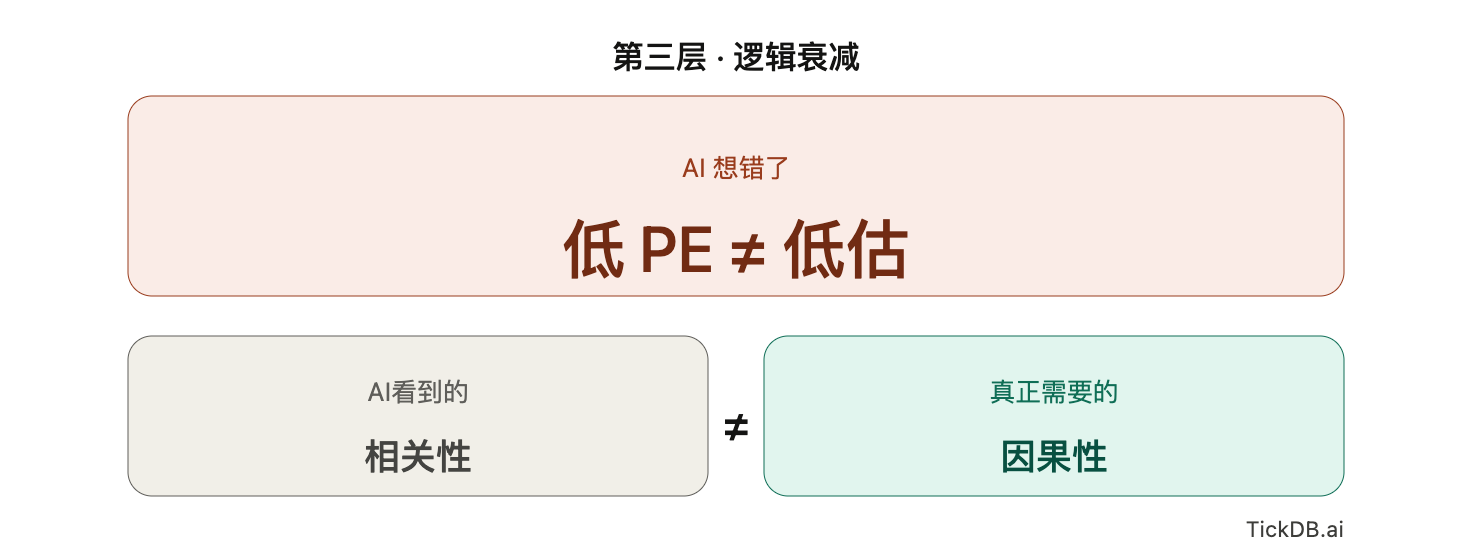
第三层:逻辑衰减——“AI想错了”
这是三层衰减中最深、也最棘手的一层。
前两层解决的是“数据对不对”,这一层解决的是“逻辑对不对”。
{kind=link}
机制
即使AI拿到了准确的结构化实时数据(第一、二层都设防了),它在筛选“低估股”时仍可能犯一个根本性错误。
因为低PE不等于低估。这不是数据错了,是逻辑错了。
一家公司PE低,有三种完全不同的可能:真的被市场情绪错杀;处于周期性盈利高峰,E即将下行;基本面已恶化,PE是跌出来的。AI默认把“低PE”等同于“低估”,这在本质上是混淆了统计相关性和经济因果性。用专业术语讲,这叫“伪相关”——历史数据里低PE和后续上涨有统计关联,但AI无法区分这种关联是因为真正的价值回归,还是因为偶然因素。
学术与行业证据
这个问题不是个例,是系统性的。
《StockBench》研究团队在2025年的一项大规模测试中,让GPT-4、Claude-4等多个主流LLM在仿真交易环境中连续运行数月。结论直白:绝大多数模型未能跑赢最简单的“等权买入持有”基准。ChatGPT做多S&P 500的策略甚至录得-0.291的负夏普比率。论文给出的诊断极其精辟:
“在静态金融问答上的成功,并不一定能转化为动态市场环境中的有效交易策略。”
另一项追踪研究发现了更具体的机制。两家业务完全无关的公司,仅因年报文本中都大量提及“供应链中断”,AI就把它们判定为高度相关并据此生成配对交易信号——这种信号在真实市场中没有丝毫经济逻辑支撑,纯属文本表面相似造成的误判。
▍硬核视角:A股市场的本地证据与海外实盘翻车记录
一份2025年的学术预印本针对中国A股市场做了专门测算:一个结合了价值因子和规模因子的策略组合,夏普比率仅为0.17,年化收益4.17%,最大回撤高达38.35%。单纯依赖“低PE+小市值”逻辑的投资者,在极端情况下承担了近四成本金的回撤风险。
在2024至2025年间的海外实盘中,已有多起AI策略的公开翻车记录:
| 案例 | 时间 | 核心原因 | 损失 |
|---|---|---|---|
| 某头部量化基金AI模型 | 2024年 | 训练数据未含地缘政治场景,宏观范式切换时模型逻辑瞬间失效 | 单月净值回撤23% |
| AI交易系统被恶意信号欺骗 | 2024年3月 | AI不理解交易对手方的操纵意图,仅机械执行基于数据模式的指令 | 亏损23亿美元 |
| ChatGPT在S&P 500做多策略 | 2025年学术测试 | 无意中选择了具有极差因子特征的股票,缺乏金融因果理解 | 夏普比率-0.291 |
权威观点
Two Sigma联合创始人David Siegel在近年的公开访谈中给出了异常直白的警告:
“围绕AI的能力存在一个炒作周期。人们不应该过度依赖AI,把它当作算法的拐杖。”
更尖锐的一句来自量化金融行业内部的反思:
“虚假相关性是量化金融行业的克星。”
学术界的判断同样不留情面:
“通用AI并不是制造Alpha的机器。它们发现的任何预测信号,都会被市场迅速套利抹平。因果性,才是终极对冲。”
正反观点
并非所有人都认为第三层衰减是AI选股的终极天花板。
支持派——以高盛和Morgan Stanley分析师为代表——认为当大量AI模型使用相似的因子挖掘方法时,拥挤本身会创造出新的市场定价错误,为AI策略进化提供新的低效空间。
但实盘证据对支持派相当不利。ChatGPT做多夏普为负、A股价值因子最大回撤38%、海外AI量化基金单月亏损23%——这些不是理论推演,是真金白银的损失记录。支持派的“拥挤创造新机会”在长周期上或许成立,但对于此时此刻裸问AI的散户来说,三层衰减叠加运行的代价是真实且即刻的。
有解吗:目前仅有部分解
行业的前沿探索集中在因果推断框架——让AI不只回答“这两个变量在历史上相关吗”,而是追问“这个变量是另一个变量变化的原因吗”。
技术上已有初步工具。DoWhy和EconML等因果推断库被引入量化研究,用于验证特定因子对资产回报的真实因果影响。实验数据显示,通过限制伪相关、加入逻辑校验后,AI因子的信息系数(IC)能获得58%至86%的提升——反向证明传统无约束AI生成的Alpha确实存在严重的逻辑衰减。
AQR Capital Management在因子构建中应用了“因果链”逻辑:基于“高应计利润→盈利操控概率升高→未来股价下跌”的因果链条来构建质量因子。这在业界属于相对成熟的做法,但仍属逻辑构建范畴,尚未达到完整的因果推断框架。
行业共识是冷静的:因果推断目前整体处于小规模实验阶段,技术障碍大,难以枚举所有混杂变量。第三层目前没有全自动解法,人类判断力必须留在决策环。
三层衰减诊断速查表
如果你用过AI荐股,现在可以把AI给你的推荐拿出来,按三层精准定位:
{kind=link}
| 你观察到的偏差 | 衰减层 | 能修吗 | 解法 |
|---|---|---|---|
| PE/PB数据和真实差异大(>20%) | 第一层:数据衰减 | 能修 | 用真实行情数据替代AI记忆 |
| PE数值接近,但口径不对(静态PE当TTM) | 第二层:结构衰减 | 能修 | 用JSON结构化的字段替代文本输入 |
| 数据准确、也读得对,但推荐后持续跑输指数 | 第三层:逻辑衰减 | 部分能修 | 因果框架探索 + 人类判断兜底 |
散户裸问AI时,三层衰减叠加运行。零层设防。
2025年浙江、四川等地证监局仍在持续对涉及AI荐股误导性宣传的投顾机构开出罚单。《生成式人工智能服务管理暂行办法》明确要求AI生成内容应当真实准确。监管在追、技术在迭代,但当前这个领域,散户自己留一个心眼仍然是最管用的风控。
搭建你自己的校验链路
零代码尝鲜
终端执行npx clawhub@latest install tickdb-market-data,在支持的对话客户端中直接查询A股实时估值。AI推荐了哪几只,就查哪几只。免费试用覆盖72个热门品种。
轻代码验证
用行情API拉取估值数据(代码见上文第一层解法),导出CSV后和AI推荐逐行对比。一套接口覆盖A股、港股、美股共40,145个品种,你只需要关心今天要校验哪几只。
进阶玩法
把行情API接入你自己的LLM推理链路,解决第一、二层衰减。文档在https://docs.tickdb.ai。项目GitHub开源,支持9大客户端集成。第三层逻辑衰减怎么修,欢迎在社区讨论。
一个提醒:任何人对你推荐“AI选股”时,先让他把推荐清单和真实行情数据对比表填好再聊。没有一个投资决策应该建立在未经验证的AI输出上。
你用AI选股时翻过哪种车?
A. AI编了PE数据 B. 推荐完第二天就暴雷 C. 至今不敢用AI选股
评论区选一个,看看哪种最多。
讨论一个开放问题:因果推断能不能成为第三层衰减的终极解法?还是金融市场的反身性注定了AI的选股信号必然自我衰减?
参考文献
2025-2026年(近期文献)
- StockBench Research, "Can LLM Agents Trade Stocks Profitably? A Multi-Model Simulation Study", 2025
- 蒂尔堡大学硕士论文, "Predicting Stock Returns Using AI Tools: Performance Evaluation on S&P 500", 2025
- 中国A股价值-规模因子策略绩效实证研究(学术预印本), 2025
- Two Sigma, David Siegel公开访谈,关于AI在量化投资中的能力边界与炒作周期,2024-2025年
- 《The Epistemological Frontier of AI in Quant Finance》,行业深度分析报告,2025年
- 浙江证监局、四川证监局,对证券投资咨询机构的行政处罚决定书(涉AI荐股),2025年
- AIMultiple, "FinanceReasoning Benchmark: 39 LLMs on Complex Financial Questions", 2026年
2023-2024年(基础文献)
- 国家金融监督管理总局,《关于加强金融领域生成式人工智能应用风险防控的通知》,2024年1月
- 国家网信办等七部委,《生成式人工智能服务管理暂行办法》,2023年8月
- U.S. SEC, Charges Against Delphia and Global Predictions for "AI Washing", 2024年3月
- European Securities and Markets Authority, "Trends, Risks and Vulnerabilities Report", 2024年
- Markelevich, A. et al., Suffolk University, "AI and Financial Data Extraction Accuracy: XBRL vs Unstructured Formats", 2024年
- 《Cross-Stock Predictability via LLM-Augmented Semantic Networks》,学术论文,2024年
2018-2023年(历史锚点)
- AIEQ ETF实盘运作数据与行业分析,2018-2023年
- Fama-French HML因子历史表现数据,2020-2022年
- AQR Capital Management,应计利润质量因子的因果链构建方法
工具与文档
- TickDB开发者文档,
https://docs.tickdb.ai
通过 TickDB API 获取实时行情数据
一个 API 接入外汇、加密货币、美股、港股、A股、贵金属和全球指数的实时行情。支持 WebSocket 低延迟推送,免费开始使用。
免费领取 API Key查看 API 文档